- 동적 계획법(Dynamic Programming)과 분할 정복(Divide and Conquer)은 서로 비슷한 알고리즘 기법이지만 ‘목적’과 '적용 대상’이 다릅니다. - 분할정복의 경우는 큰 문제를 작은 문제들로 나누어서 해결해 나아가면서 큰 수의 곱셈, 퀵 정렬 등과 같은 문제를 해결합니다. - 동적 계획법의 경우는 작은 문제들을 풀면서 그 결과를 저장해 나아가면서 전체 문제를 해결해 나가면서 최적화 문제나 최단 경로 문제등의 문제를 해결합니다.
💡 분할정복 알고리즘과 재귀함수는 모두 문제를 작은 부분으로 나누어 해결하는 ‘재귀적인 방법’을 통해 해결을 합니다.
💡 일반 재귀 호출의 경우 자기 자신을 호출하면서 문제를 해결 해 나아가기에 해결하는 과정에서 결과를 메모리에 저장합니다. 그렇기에 호출 스택과 같은 추가적인 메모리에 대한 사용이 있기에 속도가 느려질 수 있습니다. 또한 재귀 함수의 경우는 문제를 해결하는 과정이 하나의 과정(문제 해결, 분할)으로 이루어집니다.
💡 분할정복의 경우는 분할 → 정복 → 결합 과정을 통해서 해결해 나아가기에 해결하는 과정이 ‘분할’하는 과정과 ‘해결’하는 과정으로 분리되어 있습니다. 그리고 별도의 메모리를 사용하지 않고 문제를 작은 부분으로 나누어 해결하기에 속도가 상대적으로 빠릅니다.
분류
분할정복 알고리즘
재귀 함수
정의
문제를 작은 부분으로 나누어 해결하는 방법
함수 내부에서 자기 자신을 호출하여 문제를 해결하는 방법
해결 과정의 차이
문제를 작은 부분으로 분할하여 해결하는 과정과 해결하는 과정이 분리됨
자기 자신을 호출하여 문제를 해결하는 과정이 하나의 과정으로 이루어짐
속도의 차이
일반적으로 더 빠른 속도로 동작함
호출 스택 등의 추가적인 메모리를 사용하므로, 속도가 느려질 수 있음
대규모 문제에 대한 차이
대규모 문제를 해결하기 용이함
호출 스택의 한계로 인해, 대규모 문제를 해결하기 어려움
https://gamedevlog.tistory.com/58
3) 분할정복의 장단점
1. 분할정복의 장점
분류
설명
문제 해결 과정 간편
문제를 더 작고 쉬운 문제로 분할하여 해결하므로 해결 과정이 간단해지고 대규모 문제를 해결하기 용이합니다.
병렬 처리 수행
부분 문제들이 독립적이기 때문에 병렬 처리가 가능하다.
빠른 속도
분할정복을 이용하면 일반적으로 더 빠른 알고리즘을 만들 수 있다.
문제 해결 전략 명확
문제를 분할하고 각각 해결하는 방식이므로, 문제 해결 전략이 명확해진다.
2. 분할정복의 단점
분류
설명
스택 오버 플로우 문제
재귀적인 방법을 사용하므로, 스택 오버플로우 등의 문제가 발생할 수 있습니다.
추가적 메모리 필요
문제를 분할하는 과정에서 추가적인 메모리가 필요할 수 있다.
효율성이 떨어짐
분할된 부분 문제들이 같은 크기를 갖지 않을 경우, 효율성이 떨어질 수 있다.
추가 시간이 소요
분할하는 과정에서 추가적인 시간이 소요될 수 있다.
4) 분할정복 시간 복잡도
💡 분할정복 알고리즘의 시간 복잡도
- 분할정복의 시간 복잡도는 각 하위 문제의 크기가 n / b로 줄어들고, 분할되는 문제의 수가 a개인 경우, 일반적으로 다음과 같이 나타낼 수 있습니다. (a는 분할되는 문제의 수, b는 각 하위 문제의 크기, d는 분할과정을 제외한 각 문제를 해결하는 데 필요한 시간복잡도)
- T(n) = aT(n/b) + O(n^d)
-분할정복 알고리즘의 시간복잡도는 Master theorem에 따라 결정됩니다. - 분할정복 알고리즘의 시간복잡도는 빅오 표기법을 이용하였을 때 일반적으로 O(n log n)을 가집니다.
💡 [ 더 알아보기 ] 💡 시간 복잡도(Time Complexity)
- 알고리즘이 실행될 때 필요한 ‘입력 값’과 ‘연산 수행 시간’에 따라 효율적인 알고리즘을 나타내는 척도를 의미합니다.**
💡 Master theorem 란?
- T(n)을 분석하여 시간복잡도를 추정하는 데 유용한 방법입니다.
💡 빅오 표기법(Big-O notation)이란?
- 알고리즘의 입력 크기에 대해 수행 시간이 어떤 방식으로 증가하는지를 표기하는 것으로 최악의 경우의 시간 복잡도를 의미합니다.
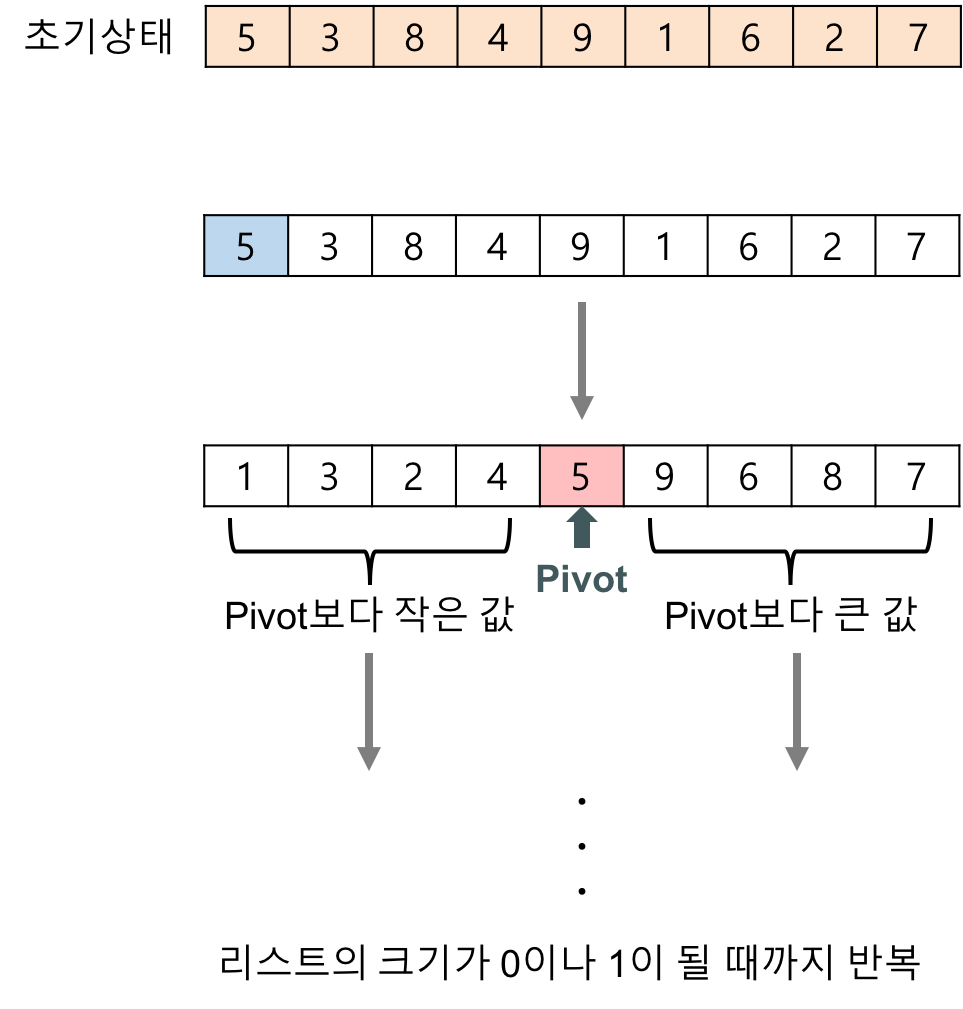
💡 퀵 정렬(Quick Sort) 수행 과정 1. 배열에서 피벗(pivot)을 선택합니다. 피벗은 배열의 중간 값이나, 첫 번째 값, 마지막 값 등 여러 기준으로 선택될 수 있습니다.
2. 피벗을 기준으로 배열을 두 개의 서브 배열로 분할합니다. 피벗보다 작은 값은 왼쪽 서브 배열에, 큰 값은 오른쪽 서브 배열에 위치시킵니다.
3. 각 서브 배열을 재귀적으로 퀵 정렬합니다.
4. 정렬된 서브 배열들을 합칩니다.
/**
* 퀵 정렬을 수행합니다.
* @param arr
* @param left
* @param right
*/publicstaticvoidquickSort(int[] arr, int left, int right){
if (left >= right) return;
int pivot = partition(arr, left, right);
quickSort(arr, left, pivot - 1);
quickSort(arr, pivot + 1, right);
}
/**
* 분할 적용 : 주어진 구간에서 피봇을 선택하고, 분할을 수행하는 함수
* @param arr
* @param left
* @param right
* @return
*/publicstaticintpartition(int[] arr, int left, int right){
int pivot = arr[left];
int i = left + 1;
int j = right;
while (i <= j) {
while (i <= right && arr[i] < pivot) i++;
while (j >= left + 1 && arr[j] > pivot) j--;
if (i > j) {
swap(arr, left, j);
} else {
swap(arr, i, j);
}
}
return j;
}
/**
* 값 변경 : 배열에서 두 원소의 위치를 바꾸는 함수
* @param arr
* @param i
* @param j
*/publicstaticvoidswap(int[] arr, int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
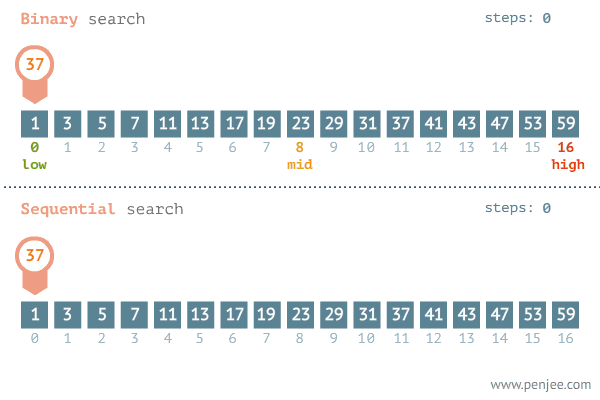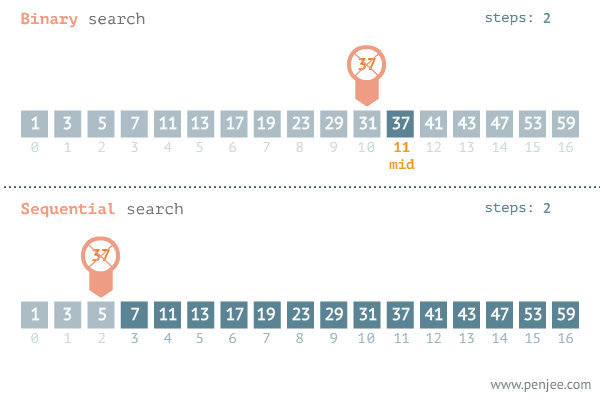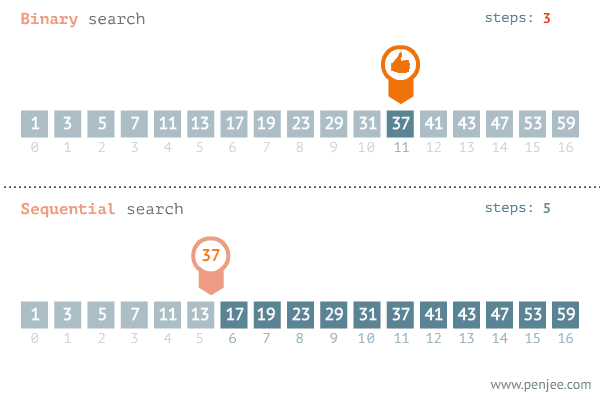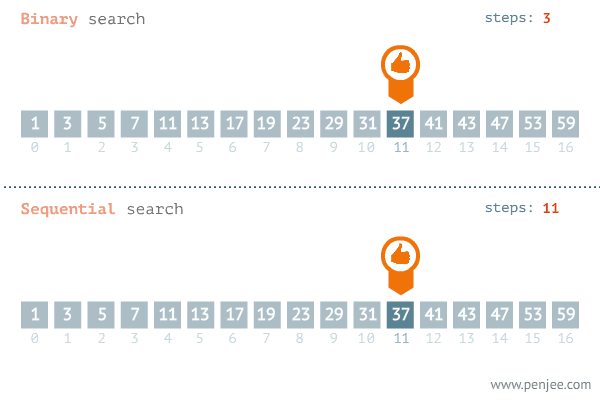
2. 이진검색 알고리즘
💡 해당 예시는 이진 검색 알고리즘을 사용하여 정렬된 정수 배열에서 특정 값을 찾는 함수입니다.
💡 분할정복의 3단계인 분할, 정복, 결합 단계 관점에서 확인해봅니다.
1. 분할 : 배열을 절반으로 나누는 과정을 수행합니다.
2. 정복 : 찾으려는 값이 절반 중 하나에 위치에 있는지 확인하는 부분 문제를 해결하는 과정을 수행합니다.
3. 결합 : 배열을 절반으로 나누고, 찾으려는 값이 절반 중 하나에 위치해 있는지 확인하는 과정을 통해 부분문제를 모아서 해결하는 원래의 해를 구하는 과정을 수행합니다.
/**
* 이진검색 알고리즘
*
* @param arr {int[]}: 전체 배열
* @param key {int}: 찾고자 하는 요소
* @return ResponseEntity<ApiResponse>
* @link
* @since 2023.05.
*/@GetMapping("/1")public ResponseEntity<ApiResponse<Object>> binSearchCourse(@RequestParamint[] arr, @RequestParamint key) {
int answer = 0;
// [STEP1] 시작 인덱스와 마지막 인덱스 값을 지정합니다.int low = 0;
int high = arr.length - 1;
// [STEP2] 마지막 인덱스를 보다 첫번째 인덱스가 같아지거나 작을 경우까지 순회합니다.while (low <= high) {
// [STEP3] 중간 값을 구합니다.int mid = (low + high) / 2;
// [CASE4-1] 중간 값보다 찾으려는 값(key)가 큰 경우 : 중간 값에 1을 더하여 오른쪽 절반을 탐색합니다.if (arr[mid] < key) {
low = mid + 1;
}
// [CASE4-2] 중간 값보다 찾으려는 값(key)가 작은 경우 : 중간값에 1을 빼서 왼쪽 절반을 탐색합니다.elseif (arr[mid] > key) {
high = mid - 1;
}
// [CASE4-3] 해당 경우가 아니면 중간값을 최종 값으로 반환합니다.else {
answer = mid;
}
}
// [STEP5] 최종 탐색을 하지 못할 경우 -1을 반환합니다.if (answer == 0) answer = -1;
ApiResponse<Object> ar = ApiResponse
.builder()
.result(answer)
.resultCode(SUCCESS_CODE)
.resultMsg(SUCCESS_MSG).build();
returnnew ResponseEntity<>(ar, HttpStatus.OK);
}