- 위에 배열 형태를 순회하면서 Map으로 구성합니다. - 주로 Counting을 하거나 동일하거나 혹은 연관된 요소끼리 묶는 작업을 수행합니다.(해시 알고리즘의 key가 중복되지 않는 특성을 이용합니다) - 해당 작업에서 Counting을 하는 작업의 경우나 합계(Sum)를 수행하는 경우 getOrDefault() 메서드를 활용합니다
/**
* 패턴 1: 동일한 요소끼리 묶어서 Counting을 합니다.
*/// 1. 배열 내의 동일한 값을 key-value 형태로 묶어서 Countingint[] nums = {3, 1, 2, 3};
Map<Integer, Integer> resultMap = new HashMap<>();
for (int num : nums) {
// [STEP2] 해시 맵 내에 구성할때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
resultMap.put(num, resultMap.getOrDefault(num, 0) + 1);
}
// 2. 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
String[] participant = {"leo", "kiki", "eden"};
Map<String, Integer> pHashMap = new HashMap<>();
for (String participantItem : participant) {
pHashMap.put(participantItem, pHashMap.getOrDefault(participantItem, 0) + 1);
}
// 3. 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
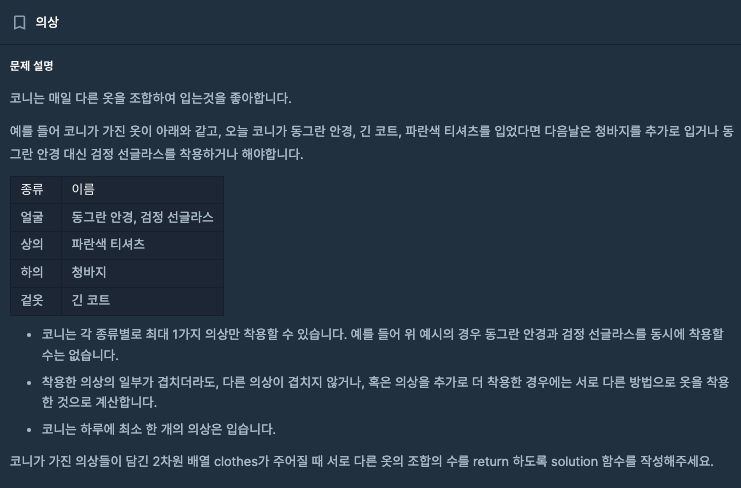
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
Map<String, Integer> resultMap2 = new HashMap<>();
for (String[] cloth : clothes) {
resultMap2.put(cloth[1], resultMap.getOrDefault(cloth[1], 0) + 1);
}
// 4. 배열 내의 비 정형 데이터를 key-value 형태로 묶어서 요소들을 추가
String[] orders = {"alex pizza pasta", "alex pizza pizza", "alex noodle", "bob pasta", "bob noodle sandwich pasta", "bob steak noodle"};
Map<String, HashSet<String>> map = new HashMap<>();
// [STEP1] 주문 배열을 순회합니다.for (String order : orders) {
// [STEP2] 주문 배열 중 이름을 추출합니다.
String[] splitOrder = order.split(" ");
String customer = splitOrder[0]; // 고객 이름// [STEP3] Hashset 내에 값이 존재하는지 확인합니다.
HashSet<String> menuSet = map.get(customer);
// [STEP4] HashSet이 존재하지 않는 경우 : null 값을 넣지 않기 위해 초기화 수행하여 값을 넣지 않습니다.if (menuSet == null) {
menuSet = new HashSet<>();
map.put(customer, menuSet);
}
// [STEP5] 주문 내용에 대해 HashSet에 중복을 제외하여 주문 내용을 넣습니다.for (int i = 1; i < splitOrder.length; i++) {
menuSet.add(splitOrder[i]); // 메뉴 추가
}
}
/**
* 패턴2 : 중복이 없는 배열 형태의 HashSet 내의 적재함.
*/
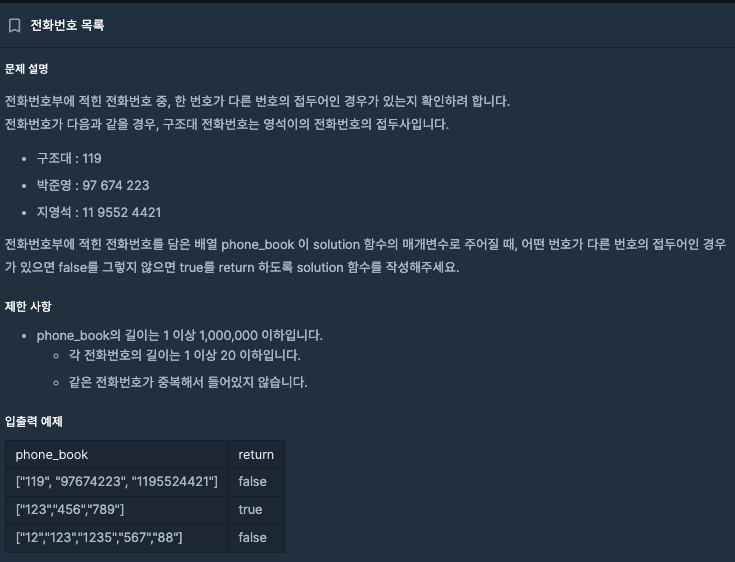
String[] phone_book = {"123", "456", "789"};
HashSet<String> hashSet = new HashSet<>();
for (String phoneBookItem : phone_book) {
hashSet.add(phoneBookItem);
}
3. 구성한 Map을 순회하면서 값을 추출하며 후 처리를 하여 결과값을 추출합니다.
💡 구성한 Map을 순회하면서 값을 추출하며 후처리를 수행하여 결과값을 추출합니다.
- Map에 대한 구성을 수행하면 다시 해당 Map에 대해 순회하며 후처리를 수행하여 결과값을 추출합니다. - 구성한 Map은 Map.Entry를 통해 감싸서 entrySet() 함수를 통해서 key-value 값을 추출합니다
// 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
String[] participant = {"leo", "kiki", "eden"};
Map<String, Integer> pHashMap = new HashMap<>();
for (String participantItem : participant) {
pHashMap.put(participantItem, pHashMap.getOrDefault(participantItem, 0) + 1);
}
// Map을 순회하면서 0이 아닌 값을 찾아서 결과로 반환합니다.for (Map.Entry<String, Integer> entry : pHashMap.entrySet()) {
if (entry.getValue() != 0) {
answer = entry.getKey();
}
}
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
Map<String, Integer> resultMap = new HashMap<>();
for (String[] cloth : clothes) {
resultMap.put(cloth[1], resultMap.getOrDefault(cloth[1], 0) + 1);
}
for (Map.Entry<String, Integer> entry : resultMap.entrySet()) {
answer *= entry.getValue() + 1;
}
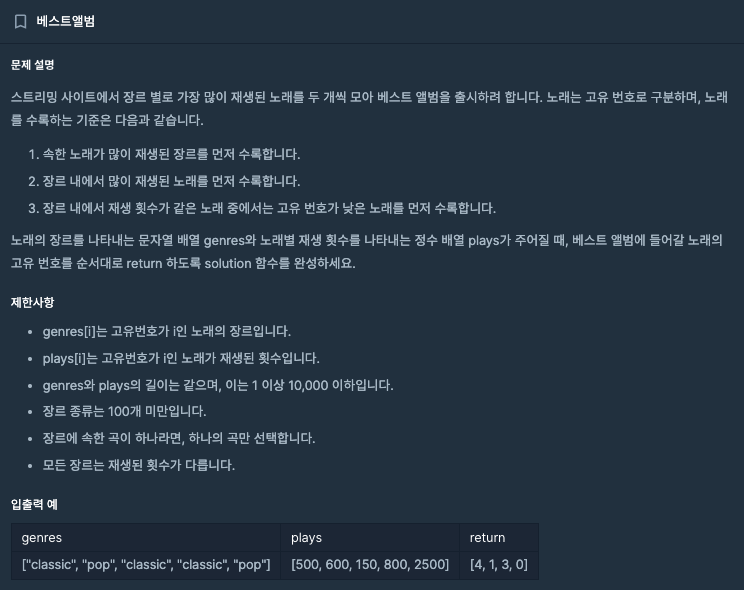
int itemCnt = 0;
for (Map.Entry<Integer, Integer> entry : list) {
if (itemCnt < 2) {
itemCnt += 1;
answerList.add(entry.getKey());
System.out.println("itemCnt :: " + itemCnt);
}
}
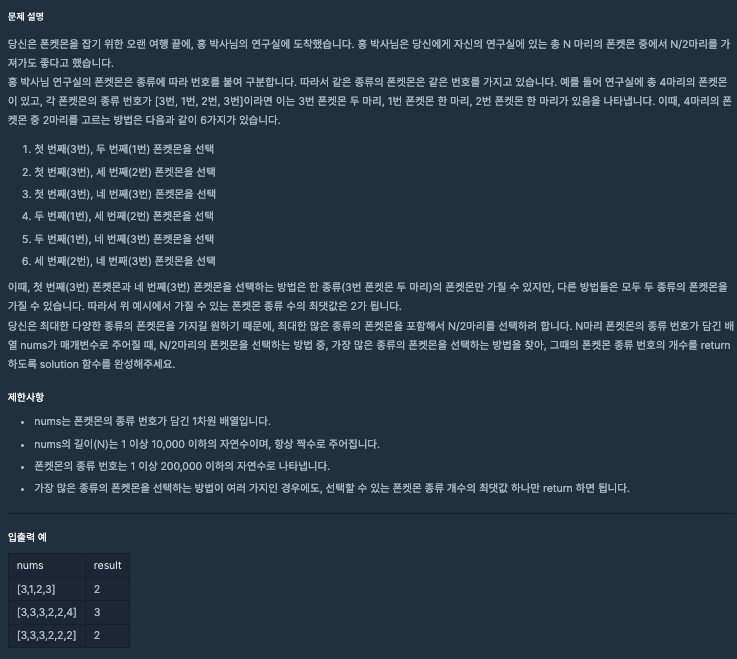
1. 리스트를 해시 맵으로 폰켓몬 번호 별로 개수를 저장하는 해시 맵을 구성 합니다 : 폰켓몬 번호(key), 폰켓몬 번호 별 개수(value)
2. 해시 맵 내에 구성할 때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
3. 폰켓몬의 종류별 개수와 최대로 얻을 수 있는 폰켓몬 개수를 구합니다.
4. 결과값을 반환합니다. - 폰켓몬의 종류보다 얻을 수 있는 개수가 많은 경우 => 폰켓몬 종류 반환 - 폰켓몬의 종류보다 얻을 수 있는 개수가 적은 경우 => 얻을 수 있는 개수 반환
/**
* [프로그래머스] Level1 - 폰켓몬
*
* @return
* @link https://school.programmers.co.kr/learn/courses/30/lessons/1845
*/@PostMapping("/1")public ResponseEntity<Object> question1(){
int answer = 0;
int[] nums = {3, 1, 2, 3};
int[] nums2 = {3, 1, 2, 3};
int[] nums3 = {3, 1, 2, 3};
// [STEP1] 폰켓몬 번호 별로 갯수를 저장하는 해시 맵을 구성합니다 : 폰켓몬 번호(key), 폰켓몬 번호 별 개수(value)
Map<Integer, Integer> resultMap = new HashMap<>();
for (int num : nums) {
// [STEP2] 해시 맵 내에 구성할때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
resultMap.put(num, resultMap.getOrDefault(num, 0) + 1);
}
System.out.println("resultMap :: " + resultMap); // {1=1, 2=1, 3=2}// [STEP3] 폰켓몬의 종류 별 개수와 최대로 얻을 수 있는 폰켓몬 개수를 구합니다.
answer = resultMap.size();
int obtainCnt = Math.abs(nums.length / 2);
// [STEP4] 결과값을 반환합니다.// 1. 폰켓몬의 종류 보다 얻을 수 있는 개수가 많은 경우 => 폰켓몬 종류 반환// 1. 폰켓몬의 종류 보다 얻을 수 있는 개수가 적은 경우 => 얻을 수 있는 개수 반환
answer = answer < obtainCnt ? answer : obtainCnt;
returnnew ResponseEntity<>(answer, HttpStatus.OK);
}