- Spring Boot 개발 환경에서 spring-kafka 라이브러리를 활용하여서 환경을 구성하였습니다.
개발 환경
버전
java
17
spring boot
3.3.7
spring boot web
3.3.7
spring-kafka
3.3.1
lombok
-
3. 의존성 추가
💡 의존성 추가
- Spring Kafka를 이용하여서 개발 환경을 구축하였습니다.
dependencies {
// Spring Boot Starter
implementation 'org.springframework.boot:spring-boot-starter' // Spring Boot
implementation 'org.springframework.boot:spring-boot-starter-web' // Spring Boot Web
implementation 'org.springframework.kafka:spring-kafka' // Spring Kafka
implementation 'org.projectlombok:lombok' // lombok
// Compile & Annotation Level
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
// Spring Boot Test
testImplementation 'org.springframework.boot:spring-boot-starter-test' // Spring Boot Test
testImplementation 'org.springframework.kafka:spring-kafka-test' // Spring Kafka Test
testRuntimeOnly 'org.junit.platform:junit-platform-launcher' // Junit5
}
4. 로깅 설정
💡 로깅 설정
- Kafka 처리의 상세한 로그를 확인하기 위해 추가적인 로깅을 설정합니다.
1. com.adjh.springbootkafka
- 프로젝트의 로깅을 DEBUG 레벨로 지정하였습니다.
2. org.apache.kafka
- Apache Kafka 관련 로그를 INFO 레벨로 설정하여 일반적인 실행 상태 정보를 확인할 수 있도록 지정하였습니다.
3. org.springframework.kafka
- Spring Kafka 관련 로그를 INFO 레벨로 설정하여 일반적인 실행 상태 정보를 확인할 수 있도록 지정하였습니다.
# Spring Kafka Logging
logging:
level:
com.adjh.springbootkafka: DEBUG
org:
apache.kafka: INFO
springframework.kafka: INFO
5. docker 컨테이너 기반 구성
💡 docker 컨테이너 기반 구성
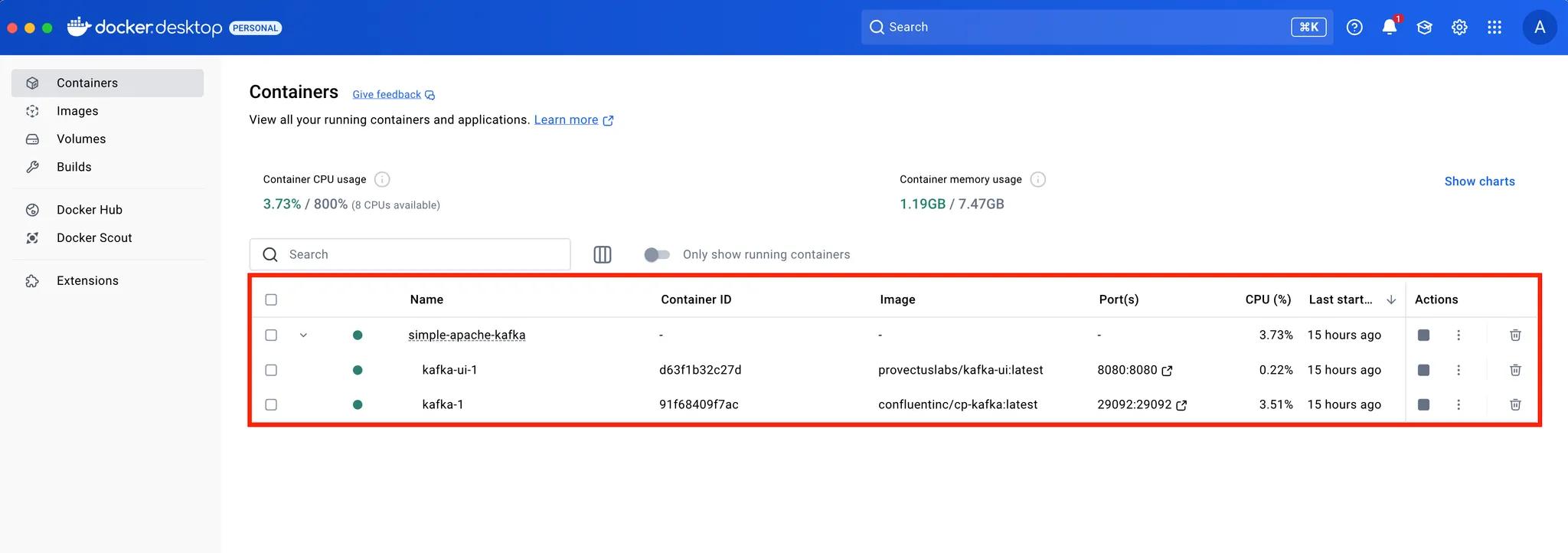
- 사전에 Docker를 통해서 생성한 컨테이너를 기반으로 이를 접근하고 관리하여 메시지를 주고받습니다.
💡 [참고] 아래와 같이 Docker Container가 구동 중인 상태입니다.
2) 환경구성 및 부분 결과 확인: 생성자(Producer)
💡 환경구성 및 부분 결과 확인: 생성자(Producer)
- 메시지를 생성하는 측인 생성자(Producer)에 대한 환경설정 및 처리 과정을 확인합니다.
1. application-kafka-loc.yaml 파일
💡 application-kafka-loc.yaml 파일 1. Server Config
- 서버 포트를 8000 포트로 지정을 하였습니다.
2. Spring Config
- spring.kafka.bootstrap-servers : Kafka 서버 접속 주소를 지정하였습니다. - spring.kafka.producer.key-serializer : 생성자의 메시지 키 값을 ‘문자열 형태로 직렬화(StringSerializer)’ 합니다. - spring.kafka.producer.value-serializer : 생성자의 메시지 값을 ‘문자열 형태로 직렬화(StringSerializer)’ 합니다.
3. Spring Kafka Logging
- 프로젝트 및 Kafka에 대한 로깅을 수행하기 위해 로깅 레벨을 지정합니다.
# Server Config
server:
port: 8000
# Spring Config
spring:
kafka:
bootstrap-servers: localhost:29092 # Kafka 접속 정보 지정
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 문자열 형태로 메시지 키 값 직렬화
value-serializer: org.apache.kafka.common.serialization.StringSerializer # 문자열 형태로 메시지 값 직렬화# Spring Kafka Logging
logging:
level:
com.adjh.springbootkafka: DEBUG
org:
apache.kafka: INFO
springframework.kafka: INFO
[ 더 알아보기 ] 💡 producer.key-serializer, producer.value-serializer는 왜 직렬화를 수행할까?
- Kafka는 네트워크를 통해 메시지를 전송하는데, Java 객체를 있는 그대로 네트워크로 전송할 수 없습니다. 따라서 바이트 스트림으로 변환(직렬화)이 필요합니다. - 또한, 서로 다른 시스템이나 언어 간에 데이터를 주고받을 때, 직렬화된 형태를 통해 호환성을 보장할 수 있습니다.
1.1. 직렬화(Serializer) 종류 및 특징
💡 직렬화(Serializer) 종류 및 특징
- 메시지를 구성하고 전송할 때 이용하는 직렬화는 메시지 형태를 바이트 스트림 형태로 변환하는 과정을 의미합니다. - 메시지를 수신하는 소비자(Consumer) 내에서도 동일하게 역직렬화를 위해서 동일한 형태로 구성해야 합니다.
직렬화 종류
설명
사용 사례
StringSerializer
문자열 데이터를 바이트로 직렬화
텍스트 메시지, 간단한 문자열 데이터
IntegerSerializer
정수형 데이터를 바이트로 직렬화
숫자 데이터, 카운터 값
LongSerializer
long 타입 데이터를 바이트로 직렬화
타임스탬프, 큰 숫자 값
ByteArraySerializer
바이트 배열을 직접 전송
이미지, 파일 등 바이너리 데이터
JsonSerializer
객체를 JSON 형식으로 직렬화
복잡한 객체, REST API 통신
AvroSerializer
Avro 형식으로 데이터 직렬화
스키마 기반 데이터, 대용량 처리
ProtobufSerializer
Protocol Buffers 형식으로 직렬화
고성능 필요 시스템, 마이크로서비스
KryoSerializer
Kryo 라이브러리를 사용한 직렬화
고성능 Java 객체 직렬화
2. KafkaTopicConfig
💡 KafkaTopicConfig
- Kafka의 토픽 설정을 담당하는 설정 파일입니다. 최초 애플리케이션이 실행될 때, 해당 토픽이 생성됩니다. 이는 지정된 Kafka 내에 Topic을 구성하였습니다.
1. test-topic-1 설정 - test-topic-1은 3개의 파티션, 복제 팩터 1, 7일의 메시지 보존 기간을 가진 Kafka 토픽입니다.
2. test-topic-2 설정 - test-topic-2는 1개의 파티션과 복제 팩터 1을 가지며 압축 정책이 적용된 Kafka 토픽입니다.
package com.adjh.springbootkafka.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.common.config.TopicConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.TopicBuilder;
/**
* Topic을 생성하는 설정 파일입니다.
*
* @author : jonghoon
* @fileName : KafkaTopicConfig
* @since : 25. 1. 10.
*/@ConfigurationpublicclassKafkaTopicConfig{
/**
* Topic 구성 예시
*
* @return NewTopic
*/@Beanpublic NewTopic exampleTopic(){
return TopicBuilder.name("test-topic-1")
.partitions(3) // 파티션 수 설정
.replicas(1) // 복제 팩터 설정 (1)
.config( // 추가 설정
TopicConfig.RETENTION_MS_CONFIG,
String.valueOf(7 * 24 * 60 * 60 * 1000L) // 7일
)
.build();
}
/**
* Topic 구성 예시
*
* @return NewTopic
*/@Beanpublic NewTopic compactTopic(){
return TopicBuilder.name("test-topic-2")
.partitions(1)
.replicas(1)
.compact() // 압축 정책 설정
.build();
}
}
💡 구성한 서버를 실행하였을 때 아래와 같이 수행이 되었습니다.
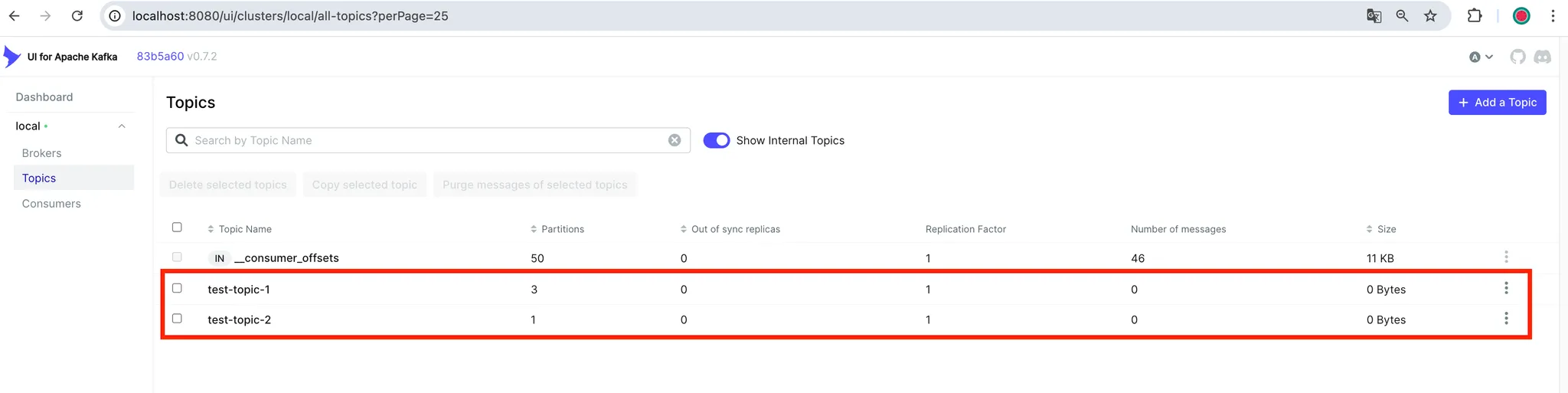
💡 Kafka-ui를 통해서 생성된 토픽을 확인합니다.
- Docker를 이용하였다면 http://localhost:8080으로 접근하시면 확인하실 수 있습니다. - 아래와 같이 구성한 test-topic-1, test-topic-2가 생성됨을 확인하였습니다.
3. KafkaProducerService
💡 KafkaProducerService - 해당 서비스는 "test-topic-1"이라는 고정된 토픽을 사용하며, KafkaTemplate을 통해 메시지를 전송합니다.
1. 기본 메시지 전송 (sendMessage)
- 가장 단순한 형태로, 메시지만을 지정된 토픽으로 전송합니다
2. 키와 함께 메시지 전송 (sendMessageWithKey)
- 메시지와 함께 키를 지정하여 전송합니다 - 키를 사용하면 동일한 키를 가진 메시지들이 같은 파티션으로 전송되도록 보장할 수 있습니다
3. 특정 파티션으로 메시지 전송 (sendMessageToPartition)
- 메시지를 특정 파티션으로 직접 전송할 수 있습니다 - 파티션을 명시적으로 지정하여 메시지의 저장 위치를 제어할 수 있습니다
4. 비동기 전송 결과 처리 (sendMessageWithCallback)
- 메시지 전송 결과를 비동기적으로 처리합니다 - 전송 성공 시 디버그 로그를 출력하고, 실패 시 에러 로그를 출력합니다
package com.adjh.springbootkafka.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
/**
* kafkaTemplate 활용한 Topic 내에 메시지를 전송하는 다양한 방법
*
* @author : jonghoon
* @fileName : KafkaProducerService
* @since : 25. 1. 10.
*/@Slf4j@ServicepublicclassKafkaProducerService{
privatefinal KafkaTemplate<String, String> kafkaTemplate;
privatefinal String topicName = "test-topic-1";
publicKafkaProducerService(KafkaTemplate<String, String> kafkaTemplate){
this.kafkaTemplate = kafkaTemplate;
}
/**
* 기본적인 메시지 전송
*
* @param message 전송 메시지
*/publicvoidsendMessage(String message){
kafkaTemplate.send(topicName, message);
}
/**
* 키와 함께 메시지 전송
*
* @param key Topic Key
* @param message 전송 메시지
*/publicvoidsendMessageWithKey(String key, String message){
kafkaTemplate.send(topicName, key, message);
}
/**
* 특정 파티션으로 메시지 전송
*
* @param message 전송 메시지
* @param partition 파티션 명
*/publicvoidsendMessageToPartition(String message, int partition){
kafkaTemplate.send(topicName, partition, null, message);
}
/**
* 비동기 전송 결과 처리
*
* @param message 전송 메시지
*/publicvoidsendMessageWithCallback(String message){
kafkaTemplate.send(topicName, message)
.whenComplete((result, ex) -> {
if (ex == null) {
log.debug("Success: {} ", result.getRecordMetadata());
} else {
log.error("Failed: {}", ex.getMessage());
}
});
}
}
4. KafkaProducerController
💡 KafkaProducerController
- KafkaProducerService를 기반으로 API를 호출받아서 메시지를 전송하는 RestController입니다.
HTTP Method
Endpoint
설명
POST
/api/v1/kafka/messages
기본 메시지를 토픽으로 전송
POST
/api/v1/kafka/messages/withKey
키와 함께 메시지를 토픽으로 전송
POST
/api/v1/kafka/messages/toPartition/{partition}
특정 파티션으로 메시지를 전송
POST
/api/v1/kafka/messages/async
비동기 방식으로 메시지를 전송
package com.adjh.springbootkafka.controller;
import com.adjh.springbootkafka.service.KafkaProducerService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
/**
* REST API 호출을 받아서 Kafka 메시지를 생성하는 생성자(Producer) 컨트롤러입니다.
*
* @author : jonghoon
* @fileName : KafkaProducerController
* @since : 25. 1. 11.
*/@Slf4j@RestController@RequestMapping("/api/v1/kafka")publicclassKafkaProducerController{
privatefinal KafkaProducerService kafkaProducerService;
publicKafkaProducerController(KafkaProducerService kafkaProducerService){
this.kafkaProducerService = kafkaProducerService;
}
/**
* 지정 토픽으로 메시지를 전송합니다.
*
* @param message 메시지
* @return
*/@PostMapping("/messages")public ResponseEntity<String> sendMessage(@RequestBody String message){
kafkaProducerService.sendMessage(message);
return ResponseEntity.ok("메시지 전송 완료");
}
/**
* 지정 토픽으로 키와 함께 메시지를 전송합니다
*
* @param key 메시지 키
* @param message 메시지
* @return
*/@PostMapping("/messages/withKey")public ResponseEntity<String> sendMessageWithKey(@RequestParam String key, @RequestBody String message){
kafkaProducerService.sendMessageWithKey(key, message);
return ResponseEntity.ok("키와 함께 메시지 전송 완료");
}
/**
* 지정 토픽 내의 특정 파티션으로 메시지를 전송합니다.
*
* @param partition 파티션 명
* @param message 메시지
* @return
*/@PostMapping("/messages/toPartition/{partition}")public ResponseEntity<String> sendMessageToPartition(@PathVariableint partition, @RequestBody String message){
kafkaProducerService.sendMessageToPartition(message, partition);
return ResponseEntity.ok("특정 파티션으로 메시지 전송 완료");
}
/**
* 지정 토픽으로 메시지를 비동기 처리 수행합니다.
*
* @param message
* @return
*/@PostMapping("/messages/async")public ResponseEntity<String> sendMessageWithCallback(@RequestBody String message){
kafkaProducerService.sendMessageWithCallback(message);
return ResponseEntity.ok("비동기 메시지 전송 요청 완료");
}
}
5. 생성자(Producer) 서버 실행
💡 생성자(Producer) 서버 실행
- 구성한 생성자 서버를 우선 실행하여, Kafka와 연결이 되는지 확인합니다. - 해당 로그 내에서는 Kafka 버전 정보, 토픽 파티션 조정, 서버 시작 정보가 출력이 되어서 애플리케이션이 성공적으로 시작되었음을 보여줍니다.
6. 메시지 전송 확인
6.1. 단순 메시지 전송
💡 단순 메시지 전송
- Kafka로 키가 없는 형태의 메시지를 전송했습니다.
💡 Kafka-UI를 통해서 확인하였을 때 메시지가 “init Message”라는 값이 test-topic-1 내에 추가됨을 확인하였습니다.
6.2. 키와 메시지를 전송
💡 키와 메시지를 전송
- Kafka로 키와 메시지 형태의 메시지를 전송했습니다.
💡 Kafka-UI를 통해서 확인하였을 때, 키가 hello이고 메시지가 “hello myworld”라는 값이 test-topic-1 내에 추가됨을 확인하였습니다.
6.3. 지정 특정 파티션 내 메시지 전송
💡 지정 특정 파티션내 메시지 전송
- 지정된 특정 파티션 내에 메시지를 전송합니다.
💡 [참고] Topic의 아이디는 토픽 내에 아래의 경로에서 확인할 수 있습니다.
- Topics > test-topic-1
💡 Kafka-UI를 통해서 확인하였을 때, 2번 파티션 내에 메시지가 “To 2 partition”이라는 값이 test-topic-1 내에 추가됨을 확인하였습니다.
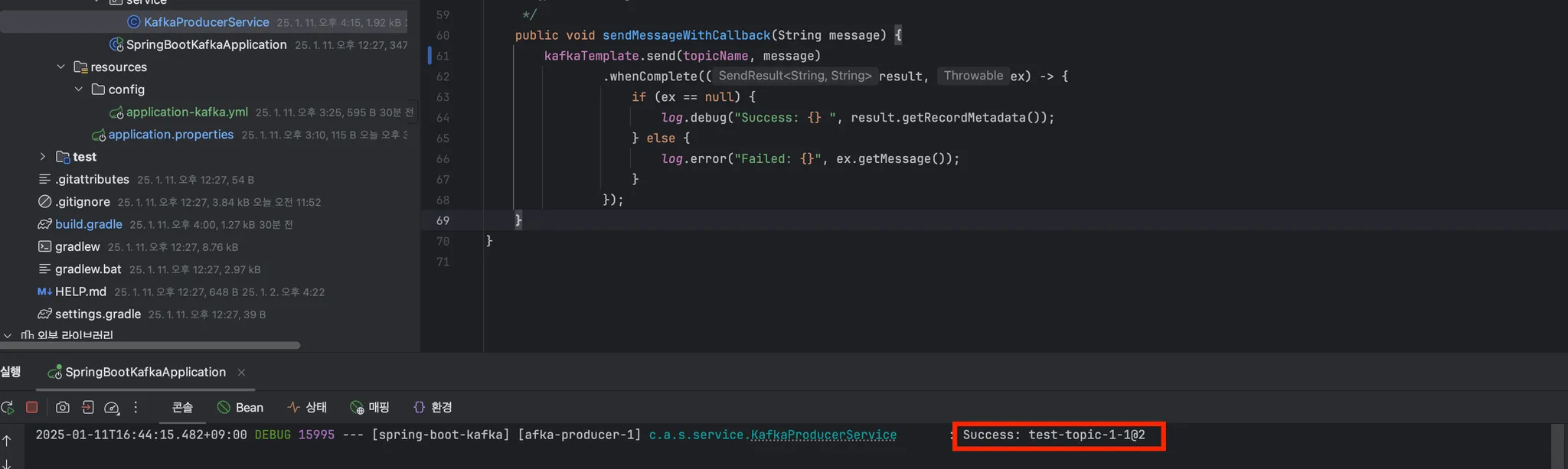
6.4. 비동기 통신 메시지 전송 (콜백 결과값 포함)
💡 비동기 통신 메시지 전송 (콜백 결과값 포함)
- Kafka로 메시지를 전송할 때 비동기 처리로 수행하는 메시지를 전송했습니다.
💡 서비스 내에 .whenComplete() 메서드를 통해, 통신 성공했을 때, 로그를 출력하도록 구성하였습니다.
- 결과적으로 정상적으로 처리되어서 값이 출력됨을 확인하였습니다.
3) 환경구성 및 부분 결과 확인: 소비자(Consumer)
💡 환경구성 및 부분 결과 확인: 소비자(Consumer)
- 메시지를 Kafka로부터 수신하는 측인 소비자(Consumer)에 대한 환경설정 및 결과를 확인합니다.
1. application-kafka-consumer.yml
💡 application-kafka-consumer.yml
1. Server Config
- 서버 포트를 8001 포트로 지정을 하였습니다.
2. Spring Config
2.1. spring.kafka.bootstrap-servers : Kafka 서버 접속 주소를 지정하였습니다.
2.2. spring.kafka.consumer.group-id : my-group이라는 Consumer들을 논리적으로 그룹화하였습니다. - 예를 들어서, 아래와 같이 시스템 별로 Group Id를 사용하면, 동일한 메시지를 각 시스템에서 독립으로 처리할 수 있습니다. - 주문 처리 시스템: order-processing-group - 알림 시스템: notification-group - 데이터 분석 시스템: analytics-group
2.3. spring.kafka.consumer.auto-offset-reset - Consumer가 저장된 offset을 찾지 못했을 때 어떻게 동작할지를 결정합니다.
2.3. spring.kafka.consumer.key-serializer : 생성자의 메시지 키 값을 ‘문자열 형태로 직렬화(StringSerializer)’ 합니다.
2.4. spring.kafka.consumer.value-serializer : 생성자의 메시지 값을 ‘문자열 형태로 직렬화(StringSerializer)’ 합니다.
3. Spring Kafka Logging
- 프로젝트 및 Kafka에 대한 로깅을 수행하기 위해 로깅 레벨을 지정합니다.
# Server Config
server:
port: 8001
# Spring Config
spring:
kafka:
bootstrap-servers: localhost:29092 # Kafka 접속 정보 지정
consumer:
group-id: my-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 문자열 형태로 메시지 키 값 역직렬화
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 문자열 형태로 메시지 값 역직렬화
# Spring Kafka Logging
logging:
level:
com.adjh.springbootkafka: DEBUG
org:
apache.kafka: INFO
springframework.kafka: INFO
💡 spring.kafka.consumer.auto-offset-reset 속성의 설정 값
설정값
설명
사용 사례
earliest
가장 처음의 offset부터 메시지를 소비
데이터 손실을 허용하지 않고 모든 메시지를 처리해야 하는 경우
latest
가장 최근의 offset부터 메시지를 소비 (기본값)
실시간 데이터 처리나 최신 메시지만 필요한 경우
none
저장된 offset을 찾지 못하면 예외 발생
엄격한 offset 관리가 필요한 경우
💡 [참고] Consumer Group
- 하나의 토픽에 대해 협력하여 메시지를 처리하는 소비자(Consumer)들의 집합을 의미합니다. 즉, 동일한 토픽을 구독하는 소비자들의 논리적인 그룹입니다.
2. XXApplication
💡 XXApplication
- Spring Boot 시작을 하는 부분에 @EnableKafka 어노테이션을 선언해 줍니다.
💡 @EnableKafka
- Spring for Apache Kafka의 핵심 어노테이션입니다. Kafka 관련 기능을 활성화하고 @KafkaListener 어노테이션을 사용할 수 있게 해주는 설정 어노테이션입니다. - @EnableKafka가 없다면 @KafkaListener 어노테이션이 동작하지 않아 Kafka로부터 메시지를 수신할 수 없게 됩니다.
💡 주요 기능
1. Kafka 리스너 컨테이너를 자동으로 생성 2. Kafka 메시지 리스닝에 필요한 인프라 구성 자동화 3. @KafkaListener 어노테이션 활성화 4. Kafka 관련 컴포넌트들의 자동 구성 지원
1. listen 1.1. @KafkaListener 어노테이션: "test-topic-1" 토픽을 구독하여 메시지를 수신합니다. 1.2. 리스너가 정상적으로 수행이 되면 “메시지 수신 : “으로 출력이 됩니다. 1.3. kafkaConsumerService의 processMessage 메서드를 호출하여 처리 결과를 반환합니다.
package com.adjh.springbootkafkaconsumer.component;
import com.adjh.springbootkafkaconsumer.service.KafkaConsumerService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* Kafka 생산자(Producer)로 부터 생성된 Topic 내의 메시지를 수신합니다
*
* @author : jonghoon
* @fileName : KafkaConsumerComponent
* @since : 25. 1. 9.
*/@Slf4j@ComponentpublicclassKafkaConsumerComponent{
privatefinal KafkaConsumerService kafkaConsumerService;
publicKafkaConsumerComponent(KafkaConsumerService kafkaConsumerService){
this.kafkaConsumerService = kafkaConsumerService;
}
/**
* 기본적인 토픽 리스닝
*
* @param message 수신 메시지
*/@KafkaListener(topics = "test-topic-1")publicvoidlisten(String message){
try {
log.info("메시지 수신: {}", message);
// 비즈니스 로직 처리
String processedMessage = kafkaConsumerService.processMessage(message);
log.info("메시지 처리 완료: {}", processedMessage);
} catch (Exception e) {
log.error("메시지 처리 중 오류 발생: {}", e.getMessage(), e);
}
}
}
4. KafkaConsumerService
💡 KafkaConsumerService
- Kafka Listener를 통해서 전달받은 메시지를 비즈니스 로직 처리 합니다. - processMessage() 메서드에서는 간단하게 전달 받은 메시지를 대문자로 변환합니다.
package com.adjh.springbootkafkaconsumer.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* Kafka Listener 를 통해서 전달 받은 메시지를 비즈니스 로직 처리
*
* @author : jonghoon
* @fileName : KafkaConsumerService
* @since : 25. 1. 10.
*/@Slf4j@ServicepublicclassKafkaConsumerService{
/**
* 간단한 비즈니스 로직 처리
*
* @param message 리스너로 들어온 메시지
* @return
*/public String processMessage(String message){
try {
// 비즈니스 로직 처리 : 메시지를 대문자로 변환하여 이를 반환합니다.return message.toUpperCase();
} catch (Exception e) {
log.error("메시지 처리 중 오류 발생: {}", e.getMessage(), e);
thrownew RuntimeException("메시지 처리 실패", e);
}
}
}
5. 소비자(Consumer) 서버 실행
💡 소비자(Consumer) 서버 실행 - 구성한 소비자 서버를 우선 실행하여, Kafka와 연결이 되는지 확인합니다.
1. 서버가 실행되고, Kafka 버전과 관련 정보가 출력이 되었습니다.
2. Consumer가 'test-topic-1' 토픽을 구독하기 시작했습니다.
3. 그룹 참여 과정을 거쳐 성공적으로 그룹에 조인했습니다.
4. 파티션 할당 : test-topic-1-0, test-topic-1-1, test-topic-1-2가 각각 할당되고 각 파티션의 오프셋이 초기화되어 0부터 메시지 소비를 시작할 준비가 완료되었습니다.
6. 메시지 전송에 따르는 수신 확인
💡 메시지 전송에 따르는 수신 확인
- 생성자가 메시지를 전송하면 수신자가 이를 수신하는 형태로 구성하였습니다.
6.1. 생성자(Proceduer)의 메시지 전송
💡 생성자(Proceduer)의 메시지 전송
- 이전 Key와 value 값이 있는 메시지를 구성하여 전송하였습니다.
6.2. 수신자(Consumer)의 메시지 수신
💡 수신자(Consumer)의 메시지 수신
- 아래와 같이 메시지를 수신하고 비즈니스 로직을 수행하여서 메시지를 대문자로 바뀌는 로직이 수행됨을 확인하였습니다.
4) Java Configuration 형태의 환경 재구성
💡 Java Configuration 형태의 환경 재구성
- 위에서는 yaml 파일 내에 생성자(Proceduer), 소비자(Consumer) 설정을 모두 구성했습니다.
- yaml 파일을 사용하면 가독성이 좋고 계층 구조가 직관적이라는 장점이 있습니다. 그러나 동적 설정에 대해서는 제한적이거나 타입의 안정성이 상대적으로 떨어진다는 단점이 있습니다.
- Java Configuration 방식을 사용하면 타입에 대한 안정성이 보장되고, IDE 내에서 자동완성을 지원한다는 장점이 있습니다. 그러나 상대적으로 많은 코드가 필요하고, 가독성이 낮다는 단점이 있습니다.
- 일반적으로 간단한 설정은 yaml 파일을 사용하고, 복잡한 로직이나 타입 안정성이 중요한 설정은 Java Configuration을 사용하는 것이 권장됩니다.
1. yaml 파일과 Java Configuration 방식을 둘 다 구성한 경우 어떤 파일이 실행될까?
💡 yaml 파일과 Java Configuration 방식을 둘 다 구성한 경우 어떤 파일이 실행될까?
- 두 설정 방식이 공존할 때는 “Java Configuration의 설정”이 우선적으로 적용되며, 누락된 설정은 yaml 파일에서 보완하는 방식으로 동작합니다.
- 동일한 설정이 있는 경우, Java Configuration의 설정이 yaml 파일의 설정을 덮어씁니다. - 예를 들어서, yaml 파일에서 bootstrap-servers=localhost:29092, group-id=group1로 설정하고 Java Configuration에서 bootstrap-servers=localhost:29093만 설정만 했을 경우 - 최종적으로 bootstrap-servers=localhost:29093(Java Config), group-id=group1(yaml)이 됩니다.
2. 생성자(Producer) 설정
💡 생성자(Producer) 설정
- 기존에 yaml 파일 형태로 Kafka 연결 및 생성 데이터에 대한 환경 설정을 yaml 파일 형태로 구성하였습니다.
# Spring Config
spring:
kafka:
bootstrap-servers: localhost:29092 # Kafka 접속 정보 지정
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 문자열 형태로 메시지 키 값 직렬화
value-serializer: org.apache.kafka.common.serialization.StringSerializer # 문자열 형태로 메시지 값 직렬화
💡 기존의 yaml 파일을 Java Configuration 클래스를 구성하였습니다.
1. @Value - yaml 파일에서 정의된 Kafka 서버 주소를 주입받습니다
2. producerFactory() 메서드
- Producer 설정을 위한 Factory Bean을 생성합니다 - 메시지 생산자의 직렬화 설정과 서버 연결 설정을 담당합니다. - bootstrap 서버, key serializer, value serializer 등 기본 설정을 Map 형태로 구성합니다
3. kafkaTemplate() 메서드
- 실제 애플리케이션에서 메시지를 전송할 때 사용되는 템플릿 Bean을 생성합니다 - producerFactory를 이용하여 KafkaTemplate 인스턴스를 생성합니다
package com.adjh.springbootkafka.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.*;
import java.util.HashMap;
import java.util.Map;
/**
* Kafka 연결 설정을 관리하는 관리파일.
*
* @author : jonghoon
* @fileName : KafkaConfig
* @since : 25. 1. 9.
*/@Slf4j@Configurationpublic class. KafkaConfig {
// Kafka 연결 서버 주소@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;
/**
* Producer 설정을 위한 Factory Bean
* - 메시지 생산자의 직렬화 설정 및 서버 연결 설정을 담당
*
* @return ProducerFactory<String, String>
*/@Beanpublic ProducerFactory<String, String> producerFactory(){
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
returnnew DefaultKafkaProducerFactory<>(props);
}
/**
* Kafka 메시지를 전송하기 위한 템플릿 Bean
* 실제 애플리케이션에서 메시지 전송시 사용됨
*
* @return KafkaTemplate<String, String>
*/@Beanpublic KafkaTemplate<String, String> kafkaTemplate(){
returnnew KafkaTemplate<>(producerFactory());
}
}
3. 소비자(Consumer) 설정
💡 소비자(Consumer) 설정
- 기존에 yaml 파일 형태로 Kafka 연결 및 그룹 지정 및 데이터 수신 데이터 역직렬화에 대해 yaml 파일 형태로 구성하였습니다.
# Spring Config
spring:
kafka:
bootstrap-servers: localhost:29092 # Kafka 접속 정보 지정
consumer:
group-id: my-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 문자열 형태로 메시지 키 값 역직렬화
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 문자열 형태로 메시지 값 역직렬화
💡 기존의 yaml 파일을 Java Configuration 클래스를 구성하였습니다. 1. @Value
- yaml 파일에서 정의된 Kafka 서버 주소를 주입받습니다
2. consumerFactory() 메서드
- Consumer 설정을 위한 Factory Bean을 생성하는 메서드입니다 - ConsumerConfig를 통한 키 갑을 통해서 서버, 그룹 아이디, Offset Reset 설정, 메시지 키 역직렬화, 메시지 키 값 역직렬화 설정을 지정하였습니다.
3. kafkaListenerContainerFactory() 메서드
- @KafkaListener 어노테이션이 붙은 메서드들을 위한 컨테이너 설정을 담당합니다 - consumerFactory를 사용하여 리스너 컨테이너를 생성합니다 - Kafka 메시지를 수신하고 처리하는데 필요한 기본 설정을 제공합니다
package com.adjh.springbootkafkaconsumer.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.*;
import org.springframework.kafka.listener.DefaultErrorHandler;
import org.springframework.util.backoff.BackOff;
import org.springframework.util.backoff.FixedBackOff;
import java.util.HashMap;
import java.util.Map;
/**
* Kafka 연결 설정을 관리하는 관리파일.
*
* @author : jonghoon
* @fileName : KafkaConfig
* @since : 25. 1. 9.
*/@Slf4j@ConfigurationpublicclassKafkaConfig{
// Kafka 연결 서버 주소@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;
/**
* Consumer 설정을 위한 Factory Bean
* 메시지 소비자의 역직렬화 설정 및 그룹 ID, 오프셋 설정을 담당
*
* @return ConsumerFactory<String, String>
*/@Beanpublic ConsumerFactory<String, String> consumerFactory(){
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
returnnew DefaultKafkaConsumerFactory<>(props);
}
/**
* Kafka Listener 컨테이너 Factory Bean
* 어노테이션 @KafkaListener 메서드들을 위한 컨테이너 설정
*
* @return ConcurrentKafkaListenerContainerFactory<String, String>
*/@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}