- 발행자(Publisher)는 데이터 스트림을 생성하고 방출(emit)하는 역할을 수행하며, Mono, Flux의 주요 타입을 제공합니다. - 구독자(Subscriber)는 발행자(Publisher)가 방출한 데이터를 수신하고 처리하는 역할을 수행합니다. - 해당 처리되는 과정을 통해 ‘데이터의 흐름이 제어’되고, 백프레셔(backpressure)를 통해 Subscriber가 처리할 수 있는 만큼의 데이터만 받을 수 있도록 보장됩니다.
1. Subscriber → Publisher : subscribe - 데이터를 받고자 하는 Subscriber는 Publisher에게 구독(subscribe)을 신청하는 단계입니다.
2. Subscription → Subscriber : onSubscribe - Publisher가 구독(subscribe) 요청을 수락하고, Subscription 객체를 통해 Subscriber에게 구독이 성공했음을 알립니다.
3. Subscriber → Subscription : request(n)/cancel - Subscriber가 처리할 수 있는 데이터의 양(n)을 지정하여 요청하거나, 필요한 경우 구독을 취소할 수 있습니다.
4. Subscription → Subscriber : onNext(data) - 요청받은 데이터를 Subscriber에게 하나씩 전달합니다
5. Subscription → Subscriber : onComplete/onError - 모든 데이터 처리가 완료되었거나 오류가 발생했을 때 Subscriber에게 알립니다.
구성 요소
설명
Publisher (발행자)
데이터 스트림을 생성하고 발행하는 주체
Subscriber (구독자)
Publisher가 발행한 데이터를 받아 처리하는 주체
Subscription
Publisher와 Subscriber 간의 통신을 조정하는 중개자
2) Publisher 반응형 데이터 타입 : Mono
💡 Publisher 반응형 데이터 타입 : Mono - Reactor 라이브러리에서 제공하는 Reactive Streams의 Publisher 중 하나로 오직 ‘0개 또는 하나의 데이터 항목 생성’하고 이 결과가 생성되고 나면 스트림이 종료되면 결과 생성을 종료합니다.
- Mono를 사용하여 비동기적으로 결과를 반환하면 해당 결과를 구독하는 클라이언트는 결과가 생성될 때까지 블로킹하지 않고 다른 작업을 수행할 수 있습니다.
public Mono<String> getData(){
// perform some database or API call to get datareturn Mono.just("example data");
}
💡 [참고] Publisher-Subscriber 패턴에서 Publisher가 단일 데이터(data)를 전송하고자 할 때 Mono를 이용합니다.
1. Mono 처리과정(Timeline)
💡Mono 처리과정
- Mono는 최대 하나의 항목을 방출한 다음 신호(값의 유무에 관계없이 성공적인 Mono)로 종료되거나 혹은 단일 신호(실패한 Mono)만 방출합니다.
1. This is the timeline of the MonoTime flows from left to right - 타임라인 흐름: Mono의 데이터는 왼쪽에서 오른쪽으로 시간순으로 처리됩니다.
2. These dotted lines and this boxindicate that a transformationis being applied to the Mono. The text inside the box showsthe nature of the transformation - 변환 과정: 점선과 박스는 Mono에 적용되는 변환 작업을 나타내며, 박스 안의 텍스트는 변환의 종류를 설명합니다.
💡 상단 흐름 (Mono 클래스 수행 처리 성공) : 하나의 데이터를 반환하는 형태
1. This is the optional item emitted by the Mono - 데이터 방출: Mono는 선택적으로 하나의 데이터 항목을 방출할 수 있습니다.
2. This vertical line indicates thatthe Mono has completed successfully - 정상 완료: 세로 선은 Mono가 성공적으로 완료되었음을 나타냅니다.
💡 하단 흐름(Mono 클래스 수행 처리 실패)
1. This Mono is the result of the transformation - 변환 결과: 변환 작업 후의 Mono는 새로운 결과값을 가집니다.
2. If for some reason the Mono terminatesabnormally, with an error, the verticalline is replaced by an X - 비정상 종료: Mono가 에러로 인해 비정상 종료되면, 세로 선 대신 X 표시로 표시됩니다. ( * 해당 부분이 발생하면 데이터 처리는 중단이 됩니다.)
[ 더 알아보기 ] 💡 If for some reason the Mono terminatesabnormally, with an error, the verticalline is replaced by an X는 무슨 의미일까?
- 즉, Mono의 실행 과정에서 에러가 발생하면 타임라인 다이어그램에서 정상 완료를 나타내는 수직선 대신 실패를 나타내는 X 표시가 나타납니다. - 예를 들어서 아래의 코드와 같습니다. 이는 map 연산 중 에러가 발생하면, Mono의 타임라인은 X로 종료되고 에러 핸들러가 호출됩니다.
package com.blog.springbootwebflux.component.mono;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Mono;
import java.time.Duration;
import java.util.Arrays;
/**
* Mono 타입의 Static Method 사용 예시
*
* @author : jonghoon
* @fileName : MonoStaticMethodExam
* @since : 24. 12. 28.
*/@Slf4j@ComponentpublicclassMonoStaticMethodExam{
publicvoidstaticMethodExam(){
// 1. delay() - 지정된 시간만큼 실행을 지연
Mono<Long> delayedMono = Mono.delay(Duration.ofSeconds(2));
delayedMono.subscribe(value -> log.debug("delay 값: {}", value));
// 2. firstWithValue() - 여러 Mono 중 첫 번째 값을 선택
Mono<String> mono1 = Mono.just("First");
Mono<String> mono2 = Mono.just("Second");
Mono<String> firstMono = Mono.firstWithValue(Arrays.asList(mono1, mono2));
firstMono.subscribe(value -> log.debug("firstWithValue 값: {}", value));
// 3. fromCallable() - Callable을 Mono로 변환
Mono<String> callableMono = Mono.fromCallable(() -> {
// 시간이 걸리는 작업 수행
Thread.sleep(1000);
return"작업 완료";
});
callableMono.subscribe(value -> log.debug("fromCallable 값: {}", value));
// 4. zip() - 여러 Mono의 결과를 결합
Mono<String> monoA = Mono.just("Hello");
Mono<String> monoB = Mono.just("World");
Mono<String> zipped = Mono.zip(monoA, monoB,
(a, b) -> a + " " + b);
zipped.subscribe(value -> log.debug("zip 값: {}", value));
}
}
💡 출력 결과
- 아래와 같이 정상적으로 출력되었으며, delay() 메서드의 경우는 특정 시간을 늦게 출력을 지정하였기에 추후에 호출이 됨을 확인하였습니다.
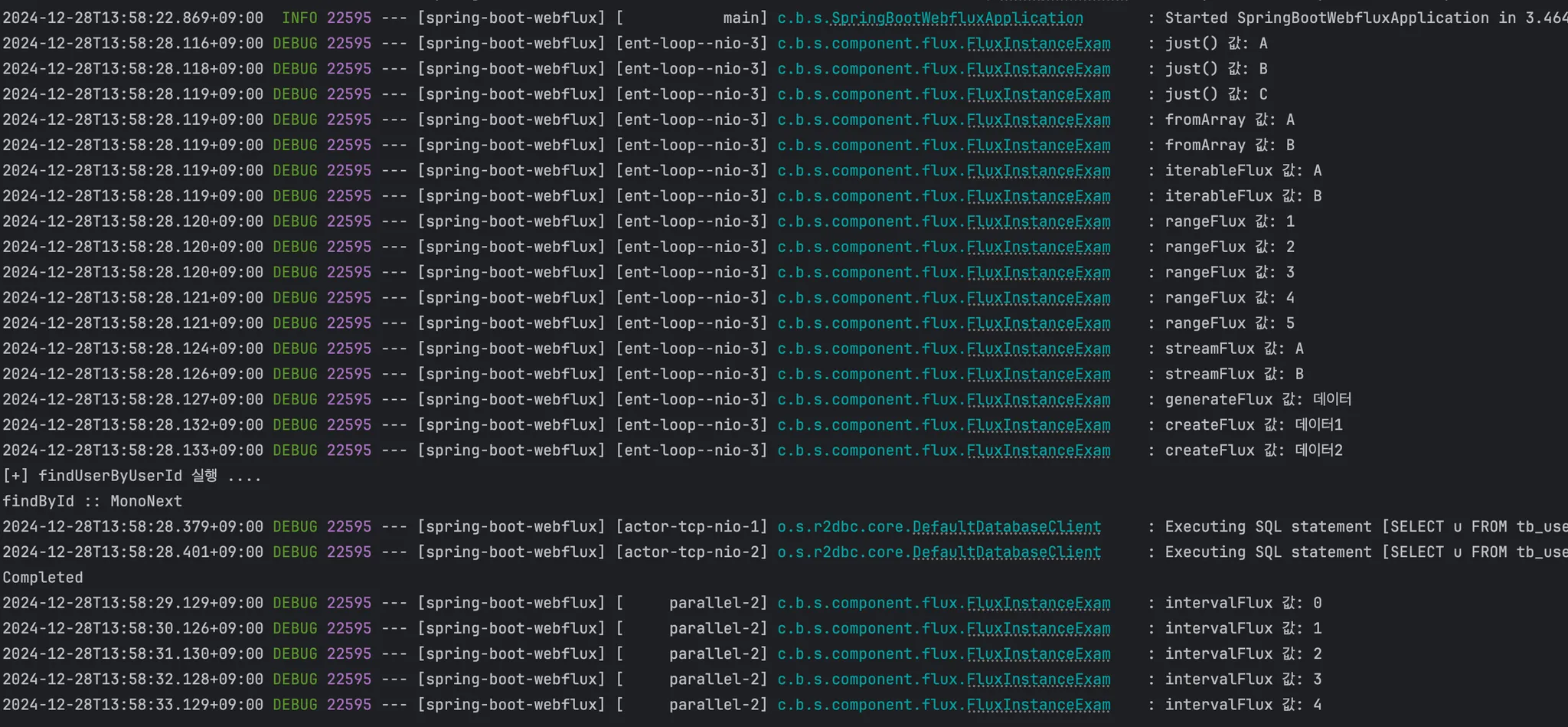
4. Mono 인스턴스 메서드
💡 인스턴스 메서드
- 객체의 인스턴스에 속하는 메서드로 인스턴스 생성 후 호출이 가능합니다. - 아래의 예시에서는 Mono.just()는 정적 메서드를 사용하여 Mono 인스턴스를 생성하고, 그 후에 인스턴스 메서드인 map()과 filter()를 체이닝 하여 데이터를 변환하고 필터링합니다.
- Reactor 라이브러리에서 제공하는 Reactive Streams의 Publisher 중 하나로 Mono와 달리 ‘여러 개의 데이터 항목’를 생성하고 스트림이 종료되면 결과 생성을 종료합니다.
- 비동기 작업을 수행하면 작업이 완료될 때까지 블로킹하지 않고 다른 작업을 수행할 수 있습니다. - Spring WebFlux에서 Flux를 사용하여 HTTP 요청을 처리하는 경우, 요청을 수신한 즉시 해당 요청을 처리하고 결과를 생성하는 대신 결과 생성이 완료될 때까지 다른 요청을 처리할 수 있습니다.
public Flux<String> getStreamedData(){
// perform a continuous stream of datareturn Flux.just("streamed data 1", "streamed data 2", "streamed data 3");
}
💡 [참고] Publisher-Subscriber 패턴에서 Publisher가 다중 데이터(data)를 전송하고자 할 때 Flux를 이용합니다.
1. Flux 처리과정(Timeline)
💡 Flux 처리과정(Timeline)
💡 상단 흐름 (성공적인 Flux) - Flux는 0~N개의 요소를 방출한 후 완료(성공적으로 또는 오류 발생)되는 반응형 스트림입니다.
1. This is the timeline of the Flux Time flows from left to right - 타임라인 흐름: Flux의 데이터는 왼쪽에서 오른쪽으로 시간순으로 처리됩니다.
2. These dotted lines and this box indicate that a transformation is being applied to the Flux. The text inside the box shows the nature of the transformation - 변환 과정: 점선과 박스는 Flux에 적용되는 변환 작업을 나타내며, 박스 안의 텍스트는 변환의 종류를 설명합니다.
💡 상단 흐름 (성공적인 Flux) : 여러개의 데이터를 반환하는 형태
1. These are the items emitted by the Flux - Flux는 여러 개의 데이터 항목을 연속적으로 방출합니다.
2. This vertical line indicates that the Flux has completed successfully - 정상 완료: 세로 선은 Flux가 성공적으로 완료되었음을 나타냅니다.
💡 하단 흐름(Flux 클래스 수행 처리 실패)
1. This Flux is the result of the transformation - 변환 결과: 변환 작업 후의 Flux는 새로운 결과값들을 가집니다.
2. If for some reason the Flux terminates abnormally, with an error, the vertical line is replaced by an X - 비정상 종료: Flux가 에러로 인해 비정상 종료되면, 세로 선 대신 X 표시로 표시됩니다. ( * 해당 부분이 발생하면 데이터 처리는 중단이 됩니다.)
💡 This Flux is the result of the transformation의 의미가 정확히 뭘까?
- 변환 작업(transformation) 이후에 생성된 새로운 Flux 스트림을 의미합니다. - 아래와 같은 예를 통해서, 원본 Flux의 각 요소를 2배로 변환한 후, 그 결과로 새로운 Flux가 생성됩니다. 이처럼 변환 작업 후에 생성되는 새로운 Flux 스트림을 "transformation의 결과"라고 표현합니다. - 이는 리액티브 프로그래밍의 불변성(immutability) 원칙을 반영하는 것으로, 원본 Flux를 직접 수정하는 대신 새로운 Flux를 생성하는 방식으로 동작합니다.
Flux.just(1, 2, 3)
.map(n -> n * 2) // 변환 작업 수행// 이 시점에서 새로운 Flux(2, 4, 6)가 생성됨
.subscribe(System.out::println);
2. Flux 인스턴스 생성
💡 Flux 인스턴스 생성
- Flux 클래스를 객체로 구성하기 위해 이를 초기값을 지정하는 과정이 인스턴스 생성입니다. - ‘여러 개의 데이터 항목’을 처리할 수 있는 Flux 클래스의 인스턴스 생성 방법들에 대해 알아봅니다.
- 객체의 인스턴스에 속하는 메서드로 인스턴스 생성 후 호출이 가능한 인스턴스 메서드입니다. - 아래의 예시에서는 Flux.just()는 정적 메서드를 사용하여 Just 인스턴스를 생성하고, 그 후에 인스턴스 메서드인 map(), filter(), flatMap() 등 체이닝 하여 데이터를 변환하고 필터링합니다.
메서드
반환 타입
설명
map()
Flux
각 요소를 변환하여 새로운 Flux를 생성합니다.
filter()
Flux
조건에 맞는 요소만 필터링합니다.
flatMap()
Flux
각 요소를 새로운 Flux로 변환하고 하나의 Flux로 병합합니다.
distinct()
Flux
중복된 요소를 제거합니다.
take(n)
Flux
처음 n개의 요소만 추출합니다.
skip(n)
Flux
처음 n개의 요소를 건너뜁니다.
merge()
Flux
여러 Flux를 하나로 병합합니다.
concat()
Flux
여러 Flux를 순차적으로 연결합니다.
zip()
Flux
여러 Flux의 요소들을 조합합니다.
reduce()
Mono
모든 요소를 결합하여 단일 결과를 생성합니다.
collectList()
Mono
모든 요소를 List로 수집합니다.
retry()
Flux
오류 발생 시 재시도합니다.
timeout()
Flux
지정된 시간 내에 요소가 생성되지 않으면 오류를 발생시킵니다.
subscribe()
void
Flux의 데이터를 구독하고 처리합니다.
package com.blog.springbootwebflux.component.flux;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
/**
* Flux Instance 메서드 사용예시
*
* @author : jonghoon
* @fileName : FluxInstanceMethodExam
* @since : 24. 12. 28.
*/@Slf4j@ComponentpublicclassFluxInstanceMethodExam{
publicvoidinstanceMethod() {
Flux<Integer> numbers = Flux.just(1, 2, 2, 3, 4, 5, 5);
numbers
// map(): 각 요소를 2배로 변환
.map(n -> n * 2)
// filter(): 짝수만 필터링
.filter(n -> n % 2 == 0)
// distinct(): 중복 제거
.distinct()
// take(): 처음 3개 요소만 선택
.take(3)
// flatMap(): 각 숫자를 문자열로 변환하고 분리
.flatMap(n -> Flux.fromArray(String.valueOf(n).split("")))
// collectList(): List로 변환
.collectList()
// subscribe(): 결과 구독 및 처리
.subscribe(
result -> System.out.println("결과: " + result),
error -> System.out.println("에러 발생: " + error),
() -> System.out.println("처리 완료")
);
numbers.subscribe(value -> log.debug("다양한 처리 결과값: {}", value));
// 여러 Flux 결합 예시
Flux<String> flux1 = Flux.just("A", "B");
Flux<String> flux2 = Flux.just("C", "D");
// merge(): 여러 Flux를 하나로 병합
Flux<String> fluxMerge = Flux.merge(flux1, flux2);
fluxMerge.subscribe(value -> log.debug("merge 값: {}", value));
// zip(): 여러 Flux 요소들을 조합
Flux<String> fluxZip = Flux.zip(flux1, flux2, (f1, f2) -> f1 + f2);
fluxZip.subscribe(value -> log.debug("zip 값: {}", value));
}
}
💡 출력 결과
- 순차적으로 데이터가 전달이 됨을 확인하였습니다.
4) Subscriber 데이터 처리 타입 : onSubscribe, onNext, onError, onComplete
💡 Subscriber 데이터 처리 타입 : onSubscribe, onNext, onError, onComplete
- 리액티브 스트림에서 데이터를 수신하고 처리하는 컴포넌트입니다. Subscriber는 다음 네 가지 주요 콜백 메서드를 통해 데이터 스트림을 처리합니다 - 이러한, 메서드들은 순차적으로 호출되며, onError나 onComplete는 스트림의 종료를 의미하므로 둘 중 하나만 호출될 수 있습니다. - 데이터의 전달은 onSubscribe → onNext(data) → onComplete/onError 순으로 처리가 됩니다.
메서드
설명
onSubscribe(Subscription s)
구독이 시작될 때 가장 먼저 호출되며, Subscription 객체를 통해 데이터 요청을 제어할 수 있습니다.
onNext(T t)
Publisher로부터 새로운 데이터가 발행될 때마다 호출되어 실제 데이터 처리를 수행합니다.
onError(Throwable t)
스트림 처리 중 에러가 발생했을 때 호출되며, 에러 처리 로직을 구현합니다.
onComplete()
모든 데이터의 처리가 성공적으로 완료되었을 때 호출됩니다.
💡 Subscriber 예시
- onSubscribe: 구독이 시작될 때 "Subscribed!" 메시지를 출력합니다. - onNext: 1부터 5까지의 각 숫자가 도착할 때마다 "Received: [숫자]"를 출력합니다. - onComplete: 모든 데이터 처리가 끝나면 "Completed!" 메시지를 출력합니다. - onError: 에러가 발생했을 경우 에러 메시지를 출력합니다 (위 예시에서는 에러가 발생하지 않습니다).
package com.blog.springbootwebflux.component;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
/**
* Please explain the class!!
*
* @author : jonghoon
* @fileName : SubscriberExam
* @since : 24. 12. 28.
*/@Slf4j@ComponentpublicclassSubscriberExam{
publicvoidsubsciberExam(){
// Publisher Flux 기반 데이터 생성
Flux<Integer> numbers = Flux.just(1, 2, 3, 4, 5);
// Subscriber 데이터 구독
numbers.subscribe(
// onNext - 각 데이터 처리
data -> log.debug("Received: " + data),
// onError - 에러 처리
error -> log.debug("Error occurred: " + error),
// onComplete - 완료 처리
() -> log.info("Completed!"),
// onSubscribe - 구독 시작 시 처리
subscription -> {
log.debug("Subscribed!");
subscription.request(Long.MAX_VALUE);
}
);
}
}
💡사용 결과
- 아래와 같이 최초 onSubscribe → onNext - onComplete 순으로 수행이 됨을 확인하였습니다.
5) Webflux 에러 핸들러(Error Handler) : Mono, Flux
💡 Webflux 에러 핸들러(Error Handler) : Mono, Flux
- Spring WebFlux에서 처리과정 중 발생하는 에러 처리를 하는 방법입니다. - Mono와 Flux에서 제공하는 다양한 에러 처리 메서드를 통해 예외 상황을 효과적으로 관리할 수 있습니다. - 또한, 전역으로 에러 핸들러를 구성하여서 중앙에서 관리할 수 있습니다.
onErrorReturn(Predicate<Throwable> predicate, T fallbackValue)
Mono<T>/Flux<T>
조건에 맞는 에러가 발생했을 때 대체값을 반환합니다.
onErrorReturn(T fallbackValue)
Mono<T>/Flux<T>
어떤 에러가 발생하든 대체값을 반환합니다.
onErrorResume(Class<E> type, Function fallback)
Mono<T>/Flux<T>
지정된 타입의 에러 발생 시 대체 Publisher를 구독합니다.
onErrorResume(Function fallback)
Mono<T>/Flux<T>
어떤 에러가 발생하든 대체 Publisher를 구독합니다.
onErrorResume(Predicate predicate, Function fallback)
Mono<T>/Flux<T>
조건에 맞는 에러 발생 시 대체 Publisher를 구독합니다.
onErrorMap(Class<E> type, Function mapper)
Mono<T>/Flux<T>
지정된 타입의 에러를 다른 에러로 변환합니다.
onErrorMap(Function mapper)
Mono<T>/Flux<T>
발생한 에러를 다른 에러로 변환합니다.
onErrorMap(Predicate predicate, Function mapper)
Mono<T>/Flux<T>
조건에 맞는 에러를 다른 에러로 변환합니다.
doOnError(Class<E> type, Consumer onError)
Mono<T>/Flux<T>
지정된 타입의 에러 발생 시 추가 동작을 실행합니다.
doOnError(Consumer onError)
Mono<T>/Flux<T>
에러 발생 시 추가 동작을 실행합니다.
doOnError(Predicate predicate, Consumer onError)
Mono<T>/Flux<T>
조건에 맞는 에러 발생 시 추가 동작을 실행합니다.
💡 사용예시 1. onErrorReturn 예시 : 값 대체 - 예시에서는 Mono의 값이 빈값일 경우 IllegalArgumentException이 발생하며, 그렇지 않으면 “기본값”이라는 문자열을 반환(onErrorReturn)합니다.
2. onErrorReturn with Predicate 예시 : 특정 오류에 대한 값 대체 - 예시에서는 Mono의 값이 빈값일 경우 IllegalArgumentException이 발생하며, 특정 지정한 에러(IllegalArgumentException) 발생 시 “빈 문자열 에러 발생”라는 값으로 대체(onErrorReturn)합니다.
3. onErrorMap: 특정 오류에 대한 커스텀 에러로 대체 - 예시에서는 Mono의 값이 빈값일 경우 IllegalArgumentException이 발생하며, Custom으로 구성한 에러(CustomException)로 대체합니다.
4. onErrorResume : 특정 publisher 데이터 타입(Mono/Flux)로 대체 - 예시에서는 Mono의 값이 빈값일 경우 IllegalArgumentException이 발생하며, 에러 발생 시 “대체 데이터(onErrorResume)"라는 값으로 반환합니다.
5. doOnError: 에러 발생시 부가적인 작업(로깅 등..)을 수행함 - 예시에서는 Mono의 값이 빈값일 경우 IllegalArgumentException이 발생하며, 로깅과 같은 부가적인 작업을 수행(doOnError)하고 최종적으로 “기본값”이라는 문자열을 반환(onErrorReturn)합니다.
💡 사용 결과 1. onErrorReturn - 해당 값이 빈값이 아니기에 Upper Case로 변환된 “DATA” 값이 출력됨을 확인하였습니다.
2. onErrorReturn with Predicate 예시 - 해당 값이 빈값이기에 IllegalArgumentException이 발생하였고, onErrorReturn에서 IllegalArgumentException가 발생하면 대체되는 “빈 문자열 에러 발생”가 출력이 됨을 확인하였습니다.
3. onErrorMap 예시 - 해당 값이 빈값이면 커스텀 오류로 처리가 되나, 빈 문자열이 아니기에 대체가 되는 “CustomException 발생 시 기본값”으로 출력이 되었습니다. 4. onErrorResume 예시 - 이를 수행하면 RuntimeException 오류가 발생하며, 오류가 발생시 대체가 되는 Publisher 타입인 Mono 객체를 반환을 함을 확인하였습니다.
5. doOnError 예시 - 이를 수행하면 RuntimeException 오류가 발생하며, 오류 발생 이후 doOnError()가 수행되어서 “에러 발생:”이 출력이 되며, 또한 "기본값"으로 리턴이 되는 것을 확인하였습니다.
💡 [참고] Mono, Flux의 에러처리를 위한 메서드에 대해 궁금하시면 아래의 글을 참고하시면 도움이 됩니다.
- 기본적인 에러 처리 방법 외에도 더 복잡한 시나리오를 처리할 수 있는 고급 에러 처리 기법을 제공합니다. - 이러한 기법들은 재시도 로직, 타임아웃 처리, 백프레셔 조절 등을 포함하며, 실제 프로덕션 환경에서 발생할 수 있는 다양한 에러 상황을 효과적으로 관리할 수 있게 해줍니다.
함수
설명
retry()
오류 발생 시 지정된 횟수만큼 재시도하는 함수입니다.
timeout()
특정 시간 내 응답이 없을 경우 TimeoutException 발생하는 함수입니다.
package com.blog.springbootwebflux.component;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.time.Duration;
/**
* Please explain the class!!
*
* @author : jonghoon
* @fileName : ErrorHandlerExam
* @since : 24. 12. 28.
*/@Slf4j@ComponentpublicclassErrorHandlerExam{
/**
* retry(), timeout()을 통해 고급 에러 처리 방법
*/publicvoidadvancedErrorHandler(){
// retry() 사용예시
Flux<Integer> fluxRetry = Flux.just(1, 2, 3)
.map(i -> {
if (i == 2) thrownew RuntimeException("Error");
return i;
})
.retry(3) // 최대 3번 재시도
.onErrorReturn(
e -> e instanceof RuntimeException, // 조건 체크0
);
fluxRetry.subscribe(value -> log.debug("처리 결과 :: {}", value));
// timeout() 사용예시
Mono<String> monoStr = Mono.just("data")
.delayElement(Duration.ofSeconds(2))
.timeout(Duration.ofSeconds(1))
.onErrorReturn("Timeout occurred");
monoStr.subscribe(value -> log.debug("처리 결과 :: {}", value));
}
}
💡 처리 결과
1. retry() 사용예시
- 순차적으로 1, 2, 3으로 구성이 된 경우에서 총 3번을 수행하도록 retry(3)을 수행합니다. - 그렇기에, 순차적인 첫 번째 시도로 1의 값을 출력하고, 3번 수행하여 2를 넘기지 못하고 1을 3번 출력하여 총 4번 출력을 하며, RuntimeException이 발생하였기에 0이라는 값을 출력합니다.
2. timeout() 사용예시
- delayElement()를 통해서 2초간 지연을 시킵니다. - timeout(Duration.ofSeconds(1))으로 1초 이내에 응답이 오지 않으면 TimeoutException이 발생하도록 설정합니다. - onErrorReturn("Timeout occurred")를 통해 TimeoutException이 발생하면 "Timeout occurred"라는 문자열을 반환합니다. - 결과적으로 2초 지연이 1초 timeout 설정보다 길어서 TimeoutException이 발생하고, "Timeout occurred"가 출력됩니다.
4. 전역 에러 핸들러 설정
💡 전역 에러 핸들러 설정 - 애플리케이션 전체에서 발생하는 예외를 중앙에서 처리하는 메커니즘입니다. Spring WebFlux에서는 WebExceptionHandler를 구현하여 전역 에러 처리를 설정할 수 있습니다.
- 애플리케이션 전체에 적용되는 일관된 에러 처리 로직을 구현할 수 있습니다. - 다양한 예외 타입에 대해 서로 다른 처리 방식을 정의할 수 있습니다. - 사용자에게 일관된 에러 응답 형식을 제공할 수 있습니다. 로깅, 모니터링 등의 부가 기능을 통합할 수 있습니다.
4.1. GlobalErrorWebExceptionHandler
💡GlobalErrorWebExceptionHandler
- 클라이언트에서 API 요청을 수행하는 경우 라우팅 되는 과정에서 전역 오류를 관리하는 Handler입니다. - 애플리케이션에서 에러가 발생하면, 이 핸들러가 @Order(-2)로 높은 우선순위를 가지고 에러를 캐치합니다. - 주요 기능은 모든 요청에 대한 에러 처리를 담당하는 역할을 수행하며, 에러 발생 시 BAD_REQUEST(400) 상태코드 반환하며 JSON 형식으로 에러 정보를 응답합니다.
1. getRoutingFunction() - 메서드에서 모든 요청(RequestPredicates.all())에 대해 renderErrorResponse 메서드를 라우팅 하도록 설정되어있습니다.
2. renderErrorResponse() - 에러 속성을 가져와서 BAD_REQUEST 상태와 함께 JSON 형식으로 응답을 생성합니다.
- 잘못된 리소스를 호출한 경우 Error인 경우 커스텀화 된 응답 코드를 반환하는 것을 확인하였습니다.
💡 사용 결과 : 400 에러
- 사용자 등록을 할 때 JSON 데이터를 포함하지 않은 경우, 아래와 같이 커스텀화된 응답 코드를 반환하는 것을 확인할 수 있습니다
6) 백프레셔(Backpressure) 제어 함수
💡 백프레셔(Backpressure) 제어 함수
- 데이터 스트림에서 Publisher와 Subscriber 간의 데이터 처리 속도 차이를 조절하는 중요한 메커니즘입니다.
- 데이터 흐름 제어: Subscriber가 처리할 수 있는 속도에 맞춰 데이터를 요청하고 수신합니다. - 메모리 관리: 과도한 데이터 적재를 방지하여 시스템의 안정성을 유지합니다. - 성능 최적화: 시스템 리소스를 효율적으로 사용하여 전체적인 성능을 향상합니다.
💡 백프레셔(Backpressure) - 데이터 스트림에서 데이터 발행자(Publisher)와 구독자(Subscriber) 사이의 데이터 처리 속도 차이를 조절하기 위한 메커니즘입니다.
- 아래의 예시와 같이 데이터 발행자(Publisher)가 데이터를 데이터 구독자(Subscriber)에게 전달(emit)을 하는 경우 발행자의 데이터 속도가 구독자 속도보다 빠를 때 발생하는 문제에 대해서 백프레셔가 이를 속도를 조절하여 처리합니다. - 이는 구독자가 처리할 수 있는 만큼의 데이터만 요청하여 시스템 과부하를 방지하며 메모리의 사용량을 효율적으로 관리하고 시스템의 안정성을 보장합니다.
- 아래의 예시에서는 데이터 구독자(Subsciber)는 데이터 발행자(Publisher)를 구독(Subscribe)하고 있습니다. - 이때 데이터 전달(emit)을 통해서 데이터 1, 데이터 2, 데이터 3, 데이터 4, 데이터 N 형태로 데이터를 전달을 받는데, 데이터 구독자(Subsciber) 보다 많은 데이터가 전달이 되는 경우 시스템 과부하가 발생할 수 있습니다.
- 이에 따라서 백프레셔에서 이를 관리합니다.
1. 백프레셔 제어 함수
백프레셔(Backpressure) 제어 함수
설명
request(n)
Subscriber가 Publisher로부터 받을 데이터의 개수를 지정합니다.
onBackpressureBuffer()
처리되지 않은 데이터를 버퍼에 저장합니다.
onBackpressureDrop()
처리할 수 없는 데이터를 버립니다.
onBackpressureLatest()
가장 최근의 데이터만 유지하고 나머지는 버립니다.
onBackpressureError()
백프레셔가 발생했을 때 오류를 발생시켜 처리합니다.
limitRate(n)
Publisher가 한 번에 전송할 수 있는 요소의 수를 제한합니다.
sample(Duration)
지정된 시간 간격으로 가장 최근 값만 전달받습니다.
2. 백프레셔 사용예시
💡 사용 예시 1. request(n) 예시 - 구독자가 한 번에 처리할 데이터의 개수를 지정합니다. 예시에서는 100개의 데이터 중 10개만 요청하여 처리합니다.
2. onBackpressureBuffer() 예시 - 처리되지 않은 데이터를 버퍼에 임시 저장합니다. 예시에서는 최대 5개까지 버퍼링 하도록 설정되어 있습니다.
3. onBackpressureDrop() 예시 - 구독자가 처리할 수 없는 데이터는 폐기합니다. 처리되지 못한 데이터는 로그로 기록됩니다. 4. onBackpressureLatest() 예시 - 가장 최근의 데이터만 유지하고 나머지는 폐기합니다. 5. limitRate(n) 예시 - Publisher가 한 번에 전송할 수 있는 데이터 개수를 제한합니다. 예시에서는 5개씩 처리하도록 설정되어 있습니다. 6. sample(Duration) 예시 - 지정된 시간 간격으로 데이터를 샘플링합니다. 예시에서는 1초 간격으로 데이터를 샘플링합니다.
package com.blog.springbootwebflux.component;
import lombok.extern.slf4j.Slf4j;
import org.reactivestreams.Subscription;
import org.springframework.stereotype.Component;
import reactor.core.publisher.BaseSubscriber;
import reactor.core.publisher.Flux;
import java.time.Duration;
/**
* 백프레셔를 관리하는 메서드를 사용한 예시
*
* @author : jonghoon
* @fileName : BackpressureExam
* @since : 24. 12. 28.
*/@Slf4j@ComponentpublicclassBackpressureExam{
publicvoidbackpressureMethod(){
// 백프레셔 제어 함수 예시 코드// 1. request(n) 예시 - 10개의 데이터만 요청
Flux.range(1, 100)
.subscribe(new BaseSubscriber<Integer>() {
@OverrideprotectedvoidhookOnSubscribe(Subscription subscription){
request(10);
}
@OverrideprotectedvoidhookOnNext(Integer value){
log.debug("Received: " + value);
}
});
// 2. onBackpressureBuffer() 예시 - 최대 5개까지 버퍼링
Flux.interval(Duration.ofMillis(1))
.onBackpressureBuffer(5)
.subscribe(value -> {
log.debug("Buffered value: " + value);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
thrownew RuntimeException(e);
}
});
// 3. onBackpressureDrop() 예시 - 처리할 수 없는 데이터는 드랍
Flux.interval(Duration.ofMillis(1))
.onBackpressureDrop(dropped ->
log.debug("Dropped value: " + dropped))
.subscribe(value -> {
log.debug("Processing: " + value);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
thrownew RuntimeException(e);
}
});
// 4. onBackpressureLatest() 예시 - 최신 데이터만 유지
Flux.interval(Duration.ofMillis(1))
.onBackpressureLatest()
.subscribe(value -> {
log.debug("Latest value: " + value);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
thrownew RuntimeException(e);
}
});
// 5. limitRate(n) 예시 - 한 번에 5개씩만 처리
Flux.range(1, 20)
.limitRate(5)
.subscribe(value ->
log.debug("Limited rate value: " + value));
// 6. sample() 예시 - 1초 간격으로 샘플링
Flux.interval(Duration.ofMillis(100))
.sample(Duration.ofSeconds(1))
.subscribe(value ->
log.debug("Sampled value: " + value));
// 7. sample() 예시 - 2초 동안 첫 번째 데이터만 처리
Flux.interval(Duration.ofMillis(500))
.sample(Duration.ofSeconds(2)) // throttleFirst와 비슷한 효과를 내기 위해 sample 사용
.subscribe(value ->
System.out.println("First value in 2 seconds: " + value));
// 8. sample() 예시 - 2초 동안 마지막 데이터만 처리
Flux.interval(Duration.ofMillis(500))
.sample(Duration.ofSeconds(2)) // throttleLast와 동일한 효과
.subscribe(value ->
System.out.println("Last value in 2 seconds: " + value));
}
}
💡 1. request(n) 사용 예시
- 1 ~ 100까지의 스트림 중에서 총 10개만 출력하도록 지정하여 콘솔상에 출력이 됩니다.
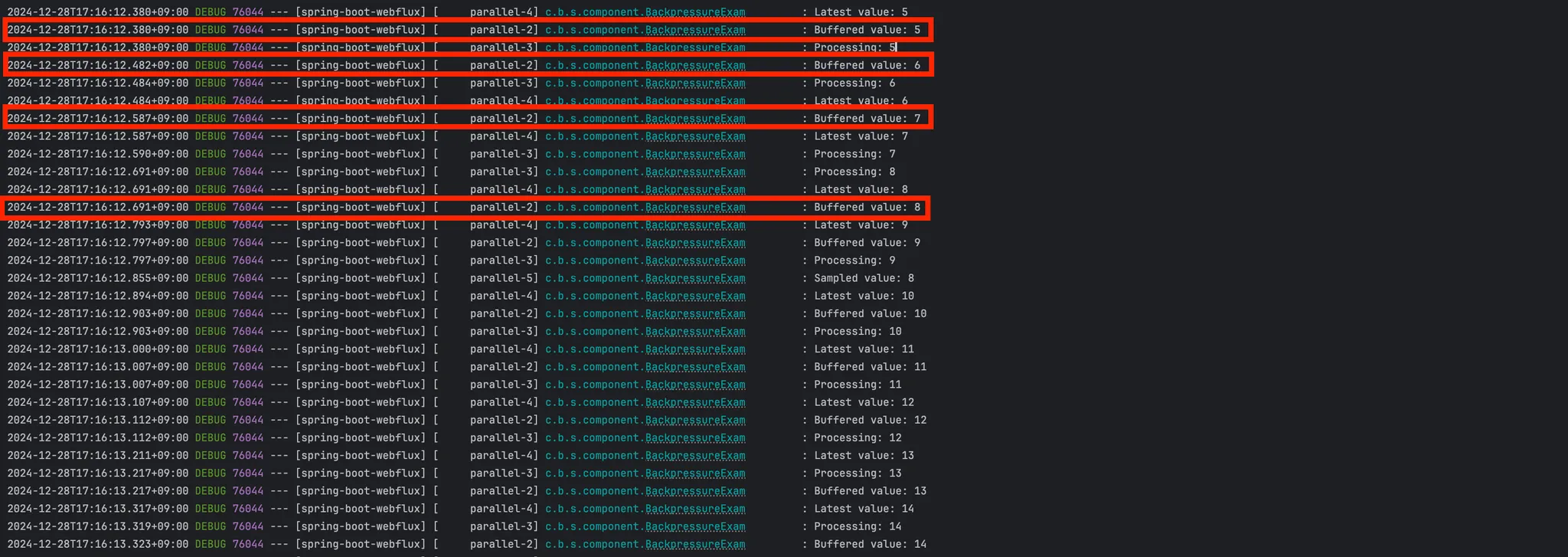
💡 2. onBackpressureBuffer() 예시
- Duration.ofMillis(1)를 통해서 1밀리 초마다 데이터를 발행을 하며, onBackpressureBuffer(5)를 통해서 버퍼를 수행합니다. - 즉, 1밀리초마다 데이터를 발행하지만 Subscriber가 처리를 제대로 하지 못하는 경우 데이터는 버퍼(임시보관소)에 최대 5개까지 보관이 됩니다.
💡 3. onBackpressureDrop() 예시
- 구독자가 처리할 수 없는 데이터는 폐기합니다. 처리되지 못한 데이터는 로그로 기록됩니다. - Duration.ofMillis(1)를 통해서 1밀리초마다 데이터를 발행을 하며, 처리되는 데이터의 경우 Processing으로 출력이 되고, 처리되지 못한 경우 폐기하는 데이터의 경우는 Dropped value로 데이터가 출력이 됩니다.
💡 4. onBackpressureLatest() 예시
- 가장 최근의 데이터만 유지하고 나머지는 폐기합니다. - Duration.ofMillis(1)를 통해서 1밀리초마다 데이터를 발행을 하며, 가장 최신데이터의 경우 Lastet Value 값으로 출력이 됩니다.
💡 5. limitRate(n) 예시
- Publisher가 한 번에 전송할 수 있는 데이터 개수를 제한합니다. 예시에서는 5개씩 처리하도록 설정되어 있습니다. - 총 범위 1에서부터 20까지 5개씩 처리하도록 설정이 되어서 콘솔상에 출력이 됩니다.
💡 6. sample(Duration) - 지정된 시간 간격으로 데이터를 샘플링합니다. 예시에서는 1초 간격으로 데이터를 샘플링합니다. - 샘플링은 연속적으로 발생하는 데이터 스트림에서 특정 시간 간격으로 데이터를 추출하는 과정을 의미합니다. - 예를 들어, 1초마다 발생하는 센서 데이터에서 5초 간격으로만 데이터를 수집하고 싶을 때 사용할 수 있습니다. - 해당 예시에서는 100밀리 초마다 데이터가 생성이 되지만 sample(Duration.ofSeconds(1))을 통해 1초 간격으로만 데이터를 수집하도록 설정되어 있습니다.