- 이전에 계산한 값을 저장하여 다시 계산하지 않도록 하여 속도를 빠르게 하는 방법입니다.
1. 메모이제이션 구성 과정
1. 입력값에 대한 결과값을 저장할 메모이제이션 테이블을 초기화합니다.
2. 함수를 호출할 때, 먼저 메모이제이션 테이블에서 해당 입력값의 결과값이 이미 저장되어 있는지 확인합니다.
3. 저장되어 있으면 해당 결과값을 반환하고, 저장되어 있지 않으면 계산을 수행하고 그 결과를 메모이제이션 테이블에 저장합니다.계산된 결과값을 반환합니다.
[ 더 알아보기 ] 💡 메모이제이션 테이블이란?
- 동적 계획법에서 사용되는 저장 공간입니다. 이전에 계산한 값을 저장해두었다가 나중에 같은 값을 계산할 때 다시 계산하지 않고 이전에 계산한 값을 활용함으로써 계산 속도를 높일 수 있습니다. - 일반적으로는 해시 테이블이나 배열 등을 사용하여 구현합니다.
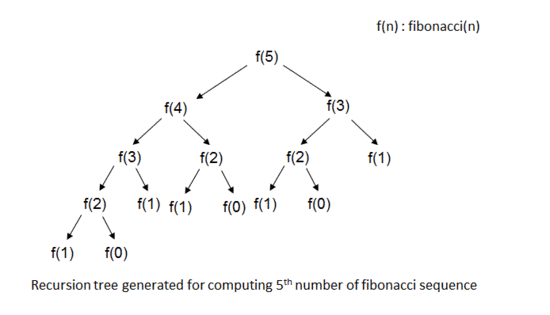
💡 [참고] 피보나치 수열을 구하기 위한 계산법 : 메모이제이션 기법
- 해당 방식은 메모이제이션 테이블에서 값이 검색되어 피보나치 수열의 계산 수행이 줄어들게 되는 방법입니다.
1. 메모이제이션 테이블을 Map 자료형을 이용하여서 구현합니다. 2. 이 때, n이 1 이하인 경우에는 n을 반환합니다. 그 외의 경우에는, 메모이제이션 테이블에서 해당 입력값의 결과값이 이미 저장되어 있는지 확인합니다. 3. 저장되어 있으면 해당 결과값을 반환하고, 저장되어 있지 않으면 피보나치 수열의 값을 계산하여 결과를 메모이제이션 테이블에 저장한 후 반환합니다.
- 함수 호출 시 스택 메모리에 할당된 공간을 벗어나게 되는 현상입니다. 이는 일반적으로 재귀 호출이 지나치게 많이 일어날 때 발생하며, 프로그램이 비정상적으로 종료됩니다. 💡 재귀적으로 수행하는 피보나치 수열과 탑다운 방식은 동일한 것이 아닐까?
- 피보나치 수열의 경우 앞의 두수를 더해가는 방법으로써 재귀적으로 수행하지만 중복 계산이 발생하여 비 효율적입니다.그러나 탑다운 방식의 경우는 중복되는 작은 문제들을 한번만 풀기에 상대적으로 효율적입니다.
💡 [참고] 피보나치 수열을 구하기 위한 계산법 : 탑다운 방식
- 동적 계획법과 비교하여서 아래의 예시는 재귀적으로 수행하며 중복 계산이 발생합니다. - 중복 계산은 예를 들어 n = 4일 경우 calcRecursiveFibonacci(3) + calcRecursiveFibonacci(2) 계산이 될때 다음 호출이 되면 동일한 값이 호출이 되어 중복 계산이 발생합니다.
/**
* 피보나치수를 이용한 경우의 수 계산방법 : 재귀함수를 이용한 방법
* @param n
* @return
*/publicstaticintcalcRecursiveFibonacci(int n) {
if (n <= 1) {
return n;
} else {
return calcRecursiveFibonacci(n - 1) + calcRecursiveFibonacci(n - 2);
}
}
publicstaticvoidmain(String[] args) {
int n = 4;
System.out.println("계단을 오르는 방식 : " + calcRecursiveFibonacci(n + 1)); // 계단을 오르는 방식 : 5
}
💡 바텀업(Bottom-Up) 방식 - ‘작은 문제’부터 해결하여 ‘큰 문제’까지 해결하는 알고리즘 방식입니다.
- 이 알고리즘의 핵심은 이전에 ‘계산한 부분 문제’의 결과를 저장해두고 나중에 같은 부분 문제가 나타날 때 다시 계산하지 않고 저장된 값을 사용하여 시간을 절약합니다. - 해당 방식은 탑 다운 방식과 비교하여 재귀적으로 수행하지 않고 ‘반복문’을 통하여서 문제를 해결해 나아가는 방식을 의미합니다.
💡 [참고] 피보나치 수열을 구하기 위한 계산법 : 바텀업 방식
- 해당 방식은 이전에 계산한 내용을 저장해두고 나중에 같은 내용이 발생할때 다시 계산하지 않고 저장된 값을 사용하여 시간을 절약하는 방법입니다.
1. memo[0]과 memo[1]은 초기값으로 설정합니다.
2. i가 2부터 n까지 반복문을 통해 memo[i] = memo[i-1] + memo[i-2]로 값을 계산하고 저장합니다.(메모이제이션)
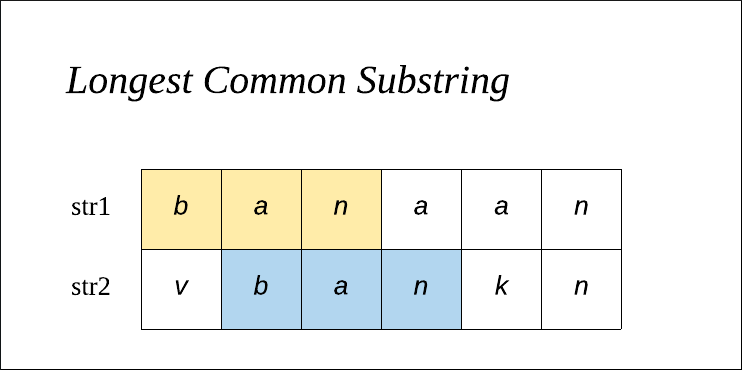
- 두 개의 문자열이 주어졌을 때, 두 문자열에서 ‘공통’으로 나타나는 ‘가장 긴 부분 문자열’을 찾는 문제입니다.
- 예를 들어, "ABCDGH"와 "AEDFHR"이 주어졌을 때, 이 두 문자열에서 공통으로 나타나는 가장 긴 부분 문자열은 "ADH"입니다.
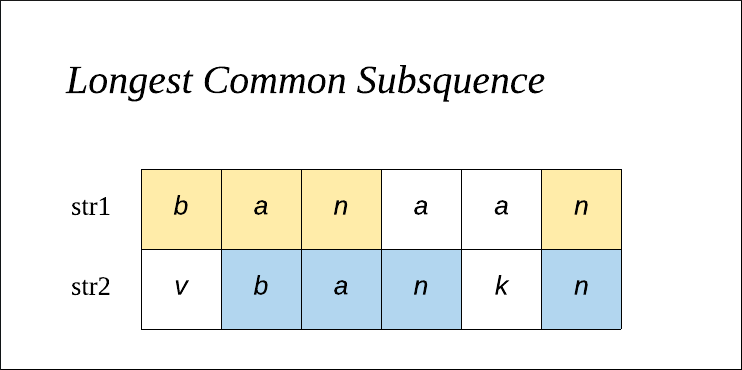
2.1. 최장 공통 수열(Longest Common Subsequence, LCS)
💡 ‘최장 공통 수열’과 ‘최장 공통 문자열’을 통하여 비교를 하여 이해합니다.
- 최장 공통 수열은 두개의 문자열 내에서 ‘서로 다른 위치에 있는 문자들’을 비교하여 가장 긴 길이의 공통 부분 수열을 찾습니다. (* 해당 경우는 연속된 문자열이 아니더라도 포함합니다)
- 최장 공통 문자열은 두개의 문자열 내에서 ‘연속적인 부분 문자열’ 중 가장 긴 길이의 공통 부분 문자열을 찾습니다. (* 해당 경우는 연속되는 문자열인 경우 포함됩니다)
[출처] https://gusdnd852.tistory.com/173
[출처] https://gusdnd852.tistory.com/173
💡 Java에서 동적 계획법을 사용하여 두 문자열의 최장 공통 부분 수열을 찾는 함수입니다.
1. LCS 함수는 문자열 A, B를 인자로 받습니다. 그리고 A와 B의 길이를 각각 m과 n에 저장합니다. opt 이차원 배열은 A와 B의 부분 문자열 간의 최장 공통 부분 수열 길이를 저장하는 배열입니다.
2. 이제 이차원 배열 opt을 계산합니다. 이는 먼저 opt의 마지막 행과 열을 0으로 설정하고, opt의 나머지 부분은 아래와 같이 계산됩니다. - A와 B의 문자가 같은 경우, opt[i][j]는 opt[i+1][j+1]+1을 대입합니다. - A와 B의 문자가 다른 경우, opt[i][j]는 opt[i+1][j]와 opt[i][j+1] 중 더 큰 값입니다.
3. 마지막으로 최장 공통 부분 수열을 찾습니다. 이를 위해 i와 j를 0으로 초기화하고, A와 B의 문자를 비교합니다. 만약 문자가 같으면, 최장 공통 부분 수열에 추가하고, i와 j를 1씩 증가시킵니다. 만약 문자가 다르면, opt[i+1][j]와 opt[i][j+1] 중 더 큰 값을 가지는 곳으로 이동합니다. 이를 반복하면 최장 공통 부분 수열을 찾을 수 있습니다.
// 두개의 문자열을 파라미터 인자로 전달합니다.
LCS("banaan", "vbankn");
/**
* 최장 공통 수열(LCS)
*
* @param A
* @param B
* @return
*/publicstatic String LCS(String A, String B) {
// 1. 전달 받은 문자열의 길이를 저장합니다. 또한 이를 저장할 이차원 배열을 구성합니다.intm= A.length();
intn= B.length();
int[][] opt = newint[m + 1][n + 1];
// 2. A, B 문자열을 역순으로 순회합니다.for (inti= m - 1; i >= 0; i--) {
for (intj= n - 1; j >= 0; j--) {
// 3. A, B 문자열을 비교합니다.if (A.charAt(i) == B.charAt(j)) {
opt[i][j] = opt[i + 1][j + 1] + 1;
} else {
opt[i][j] = Math.max(opt[i + 1][j], opt[i][j + 1]);
}
}
}
for (inti=0; i < opt.length; i++) {
System.out.println("생성된 2차원 배열 :: " + Arrays.toString(opt[i]));
}
inti=0, j = 0;
StringBuildersb=newStringBuilder();
// 3. 최장 공통 부분 수열을 찾습니다. : 문자열이 같으면 최장 공통 부분수열에 추가하고 i, j 값을 증가시킵니다.while (i < m && j < n) {
if (A.charAt(i) == B.charAt(j)) {
sb.append(A.charAt(i));
i++;
j++;
} elseif (opt[i + 1][j] >= opt[i][j + 1]) {
i++;
} else {
j++;
}
}
return sb.toString();
}
[ 더 알아보기 ] 💡 동적 계획법과 최장 공통 수열 알고리즘은 무슨 연관이 있는가?
- 동적 계획법의 종류 중 ‘바텀업 방식’을 이용하여서 작은 부분 문자열에 대한 문제를 해결하고 이를 이용하여 큰 부분문자열의 결과를 계산하는 방식으로 사용이 됩니다.
💡 최장 증가 부분 수열(Longest Increasing Subsequence, LIS)이란?
- 주어진 수열에서 일부 항목을 선택하여 만들 수 있는 부분 수열 중에서, ‘원소의 크기가 증가하는 순서대로 정렬’되어 있는 가장 긴 수열을 찾는 문제입니다. - 예를 들어, 주어진 수열이 [10, 22, 9, 33, 21, 50, 41, 60, 80]인 경우, 최장 증가 부분 수열은 [10, 22, 33, 50, 60, 80]입니다.
💡 최장 감소 부분 수열(Longest Decreasing Subsequence, LDS)이란?
- 주어진 수열에서 일부 항목을 선택하여 만들 수 있는 부분 수열 중에서, ‘원소의 크기가 감소하는 순서대로 정렬’되어 있는 가장 긴 수열을 찾는 문제입니다. - 예를 들어, 주어진 수열이 [80, 60, 50, 41, 33, 22, 21, 10, 9]인 경우, 최장 감소 부분 수열은 [80, 60, 50, 41, 33, 22, 21, 10, 9]입니다.
💡 [참고] 좀 더 다양한 알고리즘에 대해 알고 싶으시면 아래의 글을 참고하시면 도움이 됩니다.