💡 In-Memory DB란? - ‘메모리’에 데이터를 저장하고 처리하는 데이터베이스이다. 전통적으로 디스크 기반의 데이터베이스와 달리, 메모리 기반으로 데이터를 처리하기 때문에 빠른 응답 시간과 처리 속도를 보장합니다.
- 데이터를 메모리에 저장하기 때문에 디스크 기반의 데이터베이스보다는 적은 양의 데이터를 저장하며, 주로 트랜잭션 처리나 분석 작업 등에서 많이 사용된다.
💡 [참고] In-Memory DB의 종류 1. Redis - 인기 있는 In-Memory 데이터베이스로, 키-값 저장소로 사용되는 것이 특징입니다. 주로 캐싱, 세션 관리, 메시지 브로커 등에 사용됩니다.
2. Memcached - 또 다른 인기 있는 In-Memory 데이터베이스입니다. 주로 분산 캐싱 시스템으로 사용되며, 웹 애플리케이션의 성능 향상을 위해 데이터를 메모리에 저장합니다. 3. Apache Ignite - 분산 In-Memory 데이터 그리드로, 대규모 데이터 처리 및 분석에 사용됩니다. 데이터를 메모리에 보관함으로써 뛰어난 성능과 확장성을 제공합니다.
4. VoltDB - 실시간 데이터베이스로, 인-메모리 기술을 사용하여 높은 처리량과 낮은 지연 시간을 제공합니다. 대규모 실시간 애플리케이션에 적합합니다.
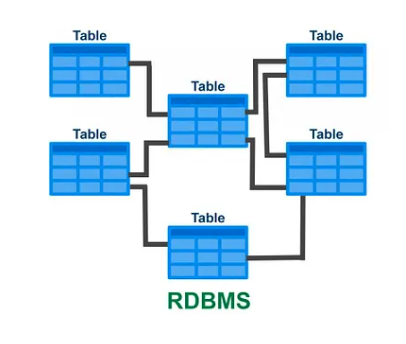
3. [참고] 관계형 데이터베이스와 다른 데이터베이스 비교
분류
RDBMS
NoSQL
In-Memory DB
데이터 모델
정형화된 데이터 모델
비정형화된 데이터 모델
정형화된 데이터 모델
데이터 스키마
정의된 스키마
자유로운 스키마
자유로운 스키마
수평적 확장
보통 어려움
용이함
용이함
수직적 확장
용이함
어려움
어려움
트랜잭션
ACID 준수
ACID 준수하지 않음
ACID 준수
성능
대규모 트랜잭션 처리에 적합
대용량의 비정형화된 데이터 처리에 적합
실시간 처리에 적합
가용성
일반적으로 높음
일반적으로 높음
일반적으로 높음
데이터 저장
디스크
디스크 또는 메모리
메모리
대표적인 제품
Oracle, MySQL, PostgreSQL
MongoDB, Cassandra, Couchbase
Redis, VoltDB, Apache Ignite
[ 더 알아보기 ] 💡수평적 확장(Horizontal Scaling)이란?
- 서버의 성능을 개선하기 위해 서버의 대수를 늘리는 방식을 의미합니다. 즉, 여러 대의 서버를 추가하는 방식입니다. 대표적인 예로는 로드 밸런싱, 샤딩 등이 있습니다. 💡 수직적 확장(Vertical Scaling)이란?
- 서버의 성능을 개선하기 위해 하드웨어를 업그레이드 하는 방식을 의미합니다. 즉, 단일 서버에서 더 많은 리소스(CPU, 메모리, 디스크 등)를 추가하는 방식입니다. 💡 ACID란? - 데이터베이스 트랜잭션을 보장하기 위한 속성으로, 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)의 약자입니다. 각 속성에 대한 설명은 다음과 같습니다.
1. 원자성(Atomicity) - 트랜잭션이 자체적으로 일련의 작업 단위로 처리되어야 하며, 이 작업 단위는 모두 성공하거나 모두 실패해야 합니다. 즉, 트랜잭션은 일부만 실행되어서는 안 됩니다. 2. 일관성(Consistency) - 트랜잭션의 실행 결과는 항상 일관적이어야 합니다. 즉, 트랜잭션을 실행하기 전과 후의 데이터 값은 일관된 상태여야 합니다. 3. 고립성(Isolation) - 동시에 실행되는 트랜잭션들은 서로 영향을 주지 않고, 각각 독립적으로 실행되어야 합니다. 이를 위해서는 트랜잭션들이 서로의 작업을 모르도록 고립시켜야 합니다. 4. 지속성(Durability) - 트랜잭션이 성공적으로 완료되었을 때, 그 결과는 영구적으로 반영되어야 합니다. 즉, 시스템이 다운되더라도 데이터는 보존되어야 합니다.
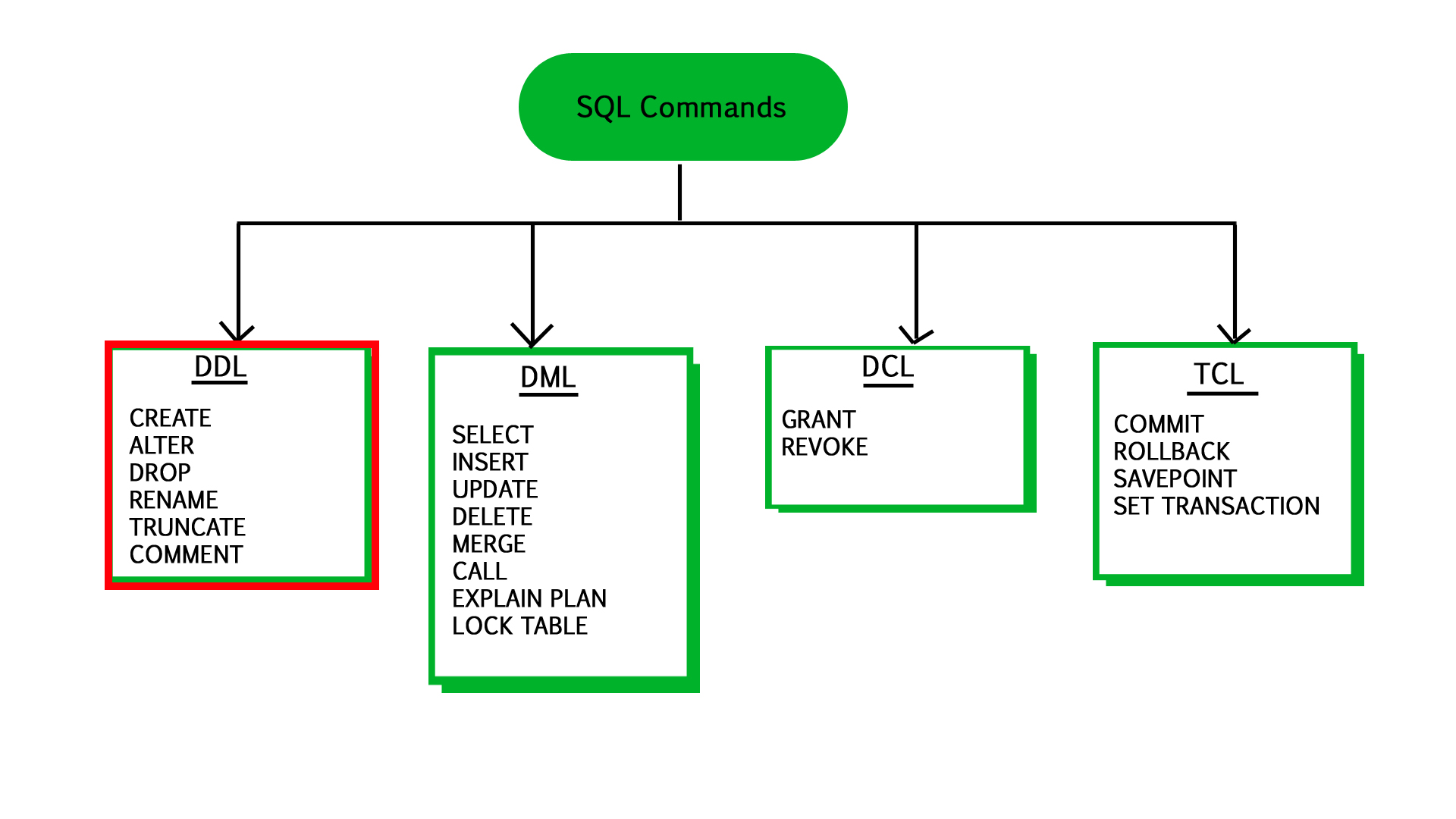
2) RDBMS의 주요 컴포넌트-1: 데이터 정의 언어(DDL: Data Definition Language)
💡 데이터 정의 언어(DDL: Data Definition Language)
- 데이터베이스에서 스키마를 정의하거나 수정하고, 테이블, 뷰, 인덱스 등의 데이터 구조를 생성하거나 변경하는 데 사용됩니다.
- 일반적으로 데이터베이스 관리 시스템(DBMS)에서 제공하는 SQL 명령어를 사용하여 DDL 작업을 수행합니다. 또한 데이터베이스의 구조를 정의하기 때문에 데이터베이스의 설계 및 관리에 매우 중요한 역할을 합니다.
- 데이터베이스 및 데이터베이스 내의 객체(테이블, 뷰, 인덱스, 프로시저, 트리거)를 ‘생성’하는데 사용되는 SQL문입니다.
-- 데이터베이스 생성
CREATE DATABASE database_name;
-- 테이블 생성
CREATE TABLE 테이블이름 (
열1 데이터_유형,
열2 데이터_유형,
...
);
-- 인덱스 생성
CREATE INDEX index_name
ON table_name (column1, column2, ...);
-- 뷰 생성
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
-- 프로시저 생성
CREATE PROCEDURE procedure_name (parameter1 datatype, parameter2 datatype, ...) AS
BEGIN ... END;
-- 트리거 생성
CREATE TRIGGER trigger_name BEFORE/AFTER INSERT
ON table_name
FOR EACH ROW
BEGIN ... END;
[ 더 알아보기 ]
💡 테이블, 뷰, 인덱스, 프로시저, 트리거들을 왜 객체라고 부르는 걸까?
- 객체라고 하는 이유는 데이터베이스에서 테이블, 뷰, 인덱스, 저장 프로시저 등이 개별적인 개체로 존재하기 때문입니다. 이러한 객체들은 각각 고유한 속성과 동작을 가지고 있으며, 데이터베이스를 구성하는 중요한 요소들입니다.
3. ALTER
💡 ALTER
- 데이터베이스 및 데이터베이스 내의 객체(테이블, 뷰, 프로시저, 트리거 등..)를 ‘수정’하는데 사용되는 SQL문입니다.
-- 데이터베이스 수정
ALTER DATABASE database_name
MODIFY NAME = new_database_name;
-- 테이블 수정
ALTER TABLE table_name
ADD column_name datatype;
-- 뷰 수정
ALTER VIEW view_name AS
SELECT new_column1, new_column2, ...
FROM table_name
WHERE condition;
-- 프로시저 수정
ALTER PROCEDURE procedure_name (new_parameter1 datatype, new_parameter2 datatype, ...);
-- 트리거 수정
ALTER TRIGGER trigger_name INSTEAD OF UPDATE
ON table_name FOR EACH ROW
BEGIN ... END;
💡 [참고] 테이블 수정과 관련된 작업 예시
작업
ALTER 문
열 추가
ALTER TABLE 테이블이름 ADD 열이름 데이터_유형;
열 이름 변경
ALTER TABLE 테이블이름 RENAME COLUMN 이전_열이름 TO 새로운_열이름;
열 데이터 유형 변경
ALTER TABLE 테이블이름 ALTER COLUMN 열이름 SET DATA TYPE 새로운_데이터_유형;
제약 조건 추가
ALTER TABLE 테이블이름 ADD CONSTRAINT 제약조건_이름 제약조건_유형 (열이름);
4. DROP
💡 DROP - 데이터베이스 및 데이터베이스 내의 객체(테이블, 뷰, 프로시저, 트리거 등..)를 ‘삭제’하는데 사용되는 SQL문입니다.
- DROP 문은 주의해서 사용해야 하며, 객체를 삭제하면 해당 객체와 관련된 데이터가 영구적으로 손실될 수 있습니다.
-- 데이터베이스 삭제
DROP DATABASE database_name;
-- 테이블 삭제
DROP TABLE table_name;
-- 인덱스 삭제
- DROP INDEX index_name ON table_name;
-- 뷰 삭제
DROP VIEW view_name;
-- 프로시저 삭제
DROP PROCEDURE procedure_name;
-- 트리거 삭제
- DROP TRIGGER trigger_name ON table_name;
5. RENAME
💡 RENAME - 데이터베이스 및 데이터베이스 내의 객체(데이터베이스, 테이블, 뷰, 프로시저, 트리거 등..)의 ‘이름을 변경’하는 데 사용되는 SQL문입니다.
-- 데이터베이스 이름 변경
ALTER DATABASE old_database_name RENAME TO new_database_name;
-- 테이블 이름 변경
ALTER TABLE old_table_name RENAME TO new_table_name;
-- 뷰 이름 변경
ALTER VIEW old_view_name RENAME TO new_view_name;
-- 인덱스 이름 변경
- ALTER INDEX old_index_name RENAME TO new_index_name;
-- 프로시저 이름 변경
ALTER PROCEDURE old_procedure_name RENAME TO new_procedure_name;
-- 트리거 이름 변경
ALTER TRIGGER old_trigger_name RENAME TO new_trigger_name;
6. TRUNCATE
💡 TRUNCATE - 데이터베이스의 ‘테이블’에서 ‘모든 데이터를 삭제’하는 데 사용되는 SQL 문입니다. 이를 사용하면 테이블의 모든 행이 삭제되지만, 테이블 자체는 삭제되지 않습니다.
💡 사용예제
- "테이블이름"은 데이터를 삭제할 테이블의 이름을 나타냅니다. TRUNCATE 문을 실행하면 해당 테이블의 모든 행이 삭제되고, 테이블은 여전히 데이터를 저장할 수 있는 상태로 유지됩니다.
TRUNCATE TABLE 테이블이름;
7. COMMENT
💡 COMMENT - 데이터베이스 객체(데이터베이스, 테이블, 컬럼, 뷰, 프로시저, 트리거)에 대한 주석을 추가하는 데 사용되는 SQL 문입니다. 주석은 데이터베이스 개체에 대한 설명, 비고, 문서화 등의 목적으로 사용될 수 있습니다.
-- 테이블 주석 추가
COMMENT ON TABLE table_name IS '주석 내용';
-- 컬럼 주석 추가
COMMENT ON COLUMN table_name.column_name IS '주석 내용';
-- 인덱스에 주석 추가
COMMENT ON INDEX index_name IS '주석 내용';
-- 뷰에 주석 추가
COMMENT ON VIEW view_name IS '주석 내용';
-- 프로시저에 주석 추가
COMMENT ON PROCEDURE procedure_name IS '주석 내용';
-- 트리거에 주석 추가
COMMENT ON TRIGGER trigger_name ON table_name IS '주석 내용';
💡 INSERT - 데이터베이스에 새로운 데이터를 삽입하는 명령어입니다. 테이블에 새로운 행을 추가할 수 있습니다.
-- INSERT: 데이터 삽입 구조
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
4. UPDATE
💡 UPDATE - 데이터베이스의 기존 데이터를 수정하는 명령어입니다. 특정 테이블의 열 값을 업데이트할 수 있습니다.
-- UPDATE: 데이터 업데이트 구조
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
5. DELETE
💡 DELETE - 데이터베이스에서 데이터를 삭제하는 명령어입니다. 특정 테이블의 행을 제거할 수 있습니다.
-- DELETE: 데이터 삭제 구조
DELETE FROM table_name
WHERE condition;
6. MERGE
💡 MERGE - 주어진 조건에 따라 데이터를 삽입, 수정 또는 삭제하는 작업을 수행하는 명령어입니다. MERGE 문은 주로 조건에 따라 데이터를 업데이트하거나 삽입하는 데 사용됩니다.
-- MERGE: 데이터 삽입 또는 업데이트 구조
MERGE INTO table_name
USING (
SELECT column1, column2, ...
FROM source_table
) source
ON (table_name.column = source.column)
WHEN MATCHED THEN
UPDATE SET column1 = source.column1, column2 = source.column2, ...
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...)
VALUES (source.column1, source.column2, ...);
7. CALL
💡 CALL - 데이터베이스 내에서 정의된 저장 프로시저, 함수 또는 사용자 정의 프로그램을 호출하는 명령어입니다.
- 저장 프로시저나 함수는 일련의 작업을 수행하고 결과를 반환할 수 있으며, CALL 문을 사용하여 이러한 저장 프로시저나 함수를 호출할 수 있습니다. 이를 통해 데이터베이스 내에서 복잡한 작업을 수행하거나 재사용 가능한 로직을 구현할 수 있습니다.
-- CALL: 저장 프로시저 또는 함수 호출 구조
CALL procedure_name(parameters);
- 데이터베이스에서 쿼리의 실행 계획을 보여주는 도구입니다. 쿼리를 실행할 때 데이터베이스가 어떻게 작업을 수행하는지를 시각적으로 보여줍니다. 이를 통해 쿼리의 성능 문제를 식별하고 최적화할 수 있습니다. - EXPLAIN PLAN 결과는 트리 형태로 표시됩니다. 루트 노드에서 시작하여 하위 계층으로 내려가는 방식으로 쿼리의 실행 계획을 보여줍니다. 각 노드는 특정 작업을 수행하는 데 필요한 정보를 포함하고 있습니다. 예를 들어, 테이블 스캔이나 인덱스 스캔, 조인 작업 등이 표시될 수 있습니다.
💡 사용 예시 - 부분에는 분석하고자 하는 쿼리를 입력하면 됩니다. - EXPLAIN PLAN 결과는 PLAN_TABLE이라는 시스템 테이블에 저장되며, 이를 조회하여 실행 계획을 확인할 수 있습니다.
-- Oracle
EXPLAIN PLAN FOR <your_query>;
-- PostgreSQL
EXPLAIN <your_query>;
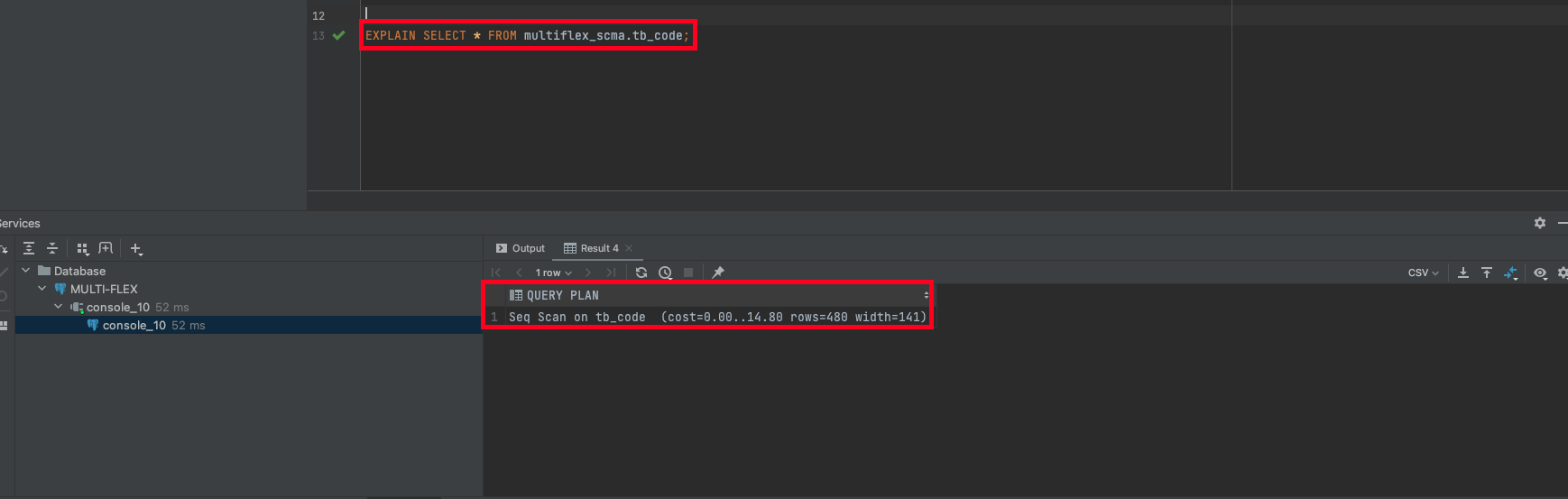
💡 PostgreSQL 환경에서 간단한 조회쿼리를 수행했을 때 Seq Scan on tb_code (cost=0.00..14.80 rows=480 width=141) 결과를 출력하였습니다.
💡 [더 알아보기] 결과 값 알아보기 Seq Scan on tb_code (cost=0.00..14.80 rows=480 width=141)
1. Seq Scan
- 시퀀셜 스캔은 테이블의 모든 데이터 블록을 순차적으로 읽어오는 방식으로 데이터를 검색합니다. 이는 인덱스를 사용하지 않고 전체 테이블을 스캔하는 방식입니다.
2. cost=0.00..14.80:
- 쿼리를 실행하는 데 소요되는 예상 비용을 나타냅니다. 비용은 쿼리 옵티마이저가 쿼리 실행에 필요한 리소스(시간, CPU, 디스크 I/O 등)를 예측하는 데 사용되는 값입니다. 여기서는 쿼리 실행에 걸리는 비용 범위를 나타냅니다.
3. rows=480
- 이 부분은 예상되는 결과 행(row) 수를 나타냅니다. 즉, tb_code 테이블에서 검색되는 행의 수를 의미합니다.
4. width=141
- 이 부분은 결과 행의 평균 너비를 나타냅니다. 즉, 각 행의 평균 크기를 의미합니다.
9. LOCK TABLE
💡 LOCK TABLE
- 데이터베이스 관리 시스템에서 테이블을 잠그는 명령입니다. 테이블이 잠기면 다른 트랜잭션이 테이블에 접근하거나 수정하는 것을 방지합니다. - 테이블에는 공유 락과 배타적 락과 같은 다양한 종류의 락을 적용할 수 있습니다. 공유 락은 여러 트랜잭션이 동시에 테이블을 읽을 수 있지만 테이블을 수정하는 것을 방지합니다. 반면에 배타적 락은 다른 트랜잭션이 테이블을 읽고 수정하는 것을 모두 방지합니다. - LOCK TABLE을 사용하는 목적은 동시에 여러 트랜잭션이 동일한 테이블에서 작업을 수행하되 서로 충돌하지 않도록 제어하고 데이터 무결성을 보장하는 것입니다. 같은 테이블에서 작업을 수행해야 하는 여러 트랜잭션의 경우 유용할 수 있습니다.
💡 사용예시
- table_name 자리에 잠그려는 테이블의 이름을 입력하면 됩니다. - READ와 WRITE는 테이블에 적용할 락의 종류를 지정하는 옵션입니다. READ는 공유 락을, WRITE는 배타적 락을 적용합니다.
LOCK TABLE table_name [READ | WRITE];
4) RDBMS의 주요 컴포넌트-3: 데이터 제어 언어(DCL: Data Control Language)
💡 데이터 제어 언어(DCL: Data Control Language)
- 데이터베이스에서 데이터의 접근 권한을 제어하는 데 사용됩니다. 주로 데이터베이스 관리 시스템(DBMS)에서 제공하는 SQL(Structured Query Language) 명령어를 사용하여 수행됩니다.
- DCL 작업은 데이터베이스의 보안과 권한 관리를 위해 매우 중요합니다. - 적절한 접근 권한을 부여하지 않으면 민감한 데이터가 노출될 수 있으며, 잘못된 접근 권한을 회수하지 않으면 보안 위험을 초래할 수 있습니다. - 따라서, DCL 작업을 신중하게 수행하기 전에 사용자의 역할과 권한을 검토하고, 필요한 경우 보안 정책을 준수하는 것이 중요합니다.
💡 GRANT - 데이터베이스 객체(테이블 또는 뷰 등)에 대한 권한을 사용자나 역할에게 부여하는 기능을 제공합니다. 이 명령어는 데이터베이스의 접근을 제어하고, 사용자나 역할이 객체에서 수행할 수 있는 작업을 결정하는 데 사용됩니다.
- 특정 권한을 부여함으로써, 사용자나 역할이 데이터베이스 내에서 어떤 수준의 접근 권한을 갖게 될지 정의할 수 있습니다. - DCL GRANT 명령어를 사용하기 위해서는 부여할 권한, 권한을 부여할 객체, 그리고 권한을 부여할 사용자나 역할을 명시해야 합니다.
-- GRANT: 사용자에게 특정 권한을 부여
GRANT privilege_name
ON object_name
TO user_name;
-- 사용자에게 테이블에 대한 SELECT, INSERT, UPDATE, DELETE 권한을 부여합니다.
GRANT SELECT, INSERT, UPDATE, DELETE
ON 테이블명
TO 사용자명;
권한
설명
SELECT
데이터베이스 객체에서 데이터를 읽을 수 있는 권한
INSERT
데이터베이스 객체에 새로운 데이터를 추가할 수 있는 권한
UPDATE
데이터베이스 객체의 데이터를 수정할 수 있는 권한
DELETE
데이터베이스 객체에서 데이터를 삭제할 수 있는 권한
3. REVOKE
💡 REVOKE - 사용자나 역할에게 부여된 권한을 취소하는 기능을 제공합니다. 이 명령어를 사용하여 데이터베이스 객체에 대한 권한을 제거하거나 사용자의 접근 권한을 제한할 수 있습니다.
- REVOKE 명령어를 사용하기 위해서는 취소할 권한, 권한을 취소할 객체, 그리고 권한을 취소할 사용자나 역할을 명시해야 합니다.
-- REVOKE: 사용자로부터 특정 권한을 취소
REVOKE privilege_name
ON object_name
FROM user_name;
-- 사용자에게 테이블에 대한 SELECT, INSERT, UPDATE, DELETE 권한을 취소합니다.
REVOKE SELECT, INSERT, UPDATE, DELETE
ON 테이블명
FROM 사용자명;
트랜잭션 내에서 특정 지점에 저장점을 설정하는 명령어. 이후 ROLLBACK 명령을 사용하여 설정한 저장점까지 되돌릴 수 있음
SET TRANSACTION
트랜잭션의 특성을 설정하는 명령어. 예를 들어, 격리 수준을 설정하거나 트랜잭션을 읽기 전용으로 지정할 수 있음
2. COMMIT
💡 COMMIT - 데이터베이스 트랜잭션에서 수행한 모든 변경사항을 영구적으로 저장하는 명령어입니다.
- 트랜잭션은 데이터베이스의 일련의 작업을 의미하며, 트랜잭션 내에서 수행한 모든 데이터 변경 작업(INSERT, UPDATE, DELETE 등)은 임시로 보관되고 있습니다. COMMIT 명령어를 수행하는 순간 임시 보관된 트랜잭션이 일괄 적용됩니다.
- 예를 들어, 특정 데이터를 삽입하는 INSERT 문을 포함하는 트랜잭션을 수행했다고 가정하였을 때, 이때 COMMIT 명령어를 실행하면 해당 INSERT 문을 통해 삽입한 데이터가 영구적으로 데이터베이스에 저장되고, 이후에도 조회나 수정 등의 작업에서 해당 데이터를 사용할 수 있게 됩니다.
-- COMMIT: 트랜잭션을 확정하고 변경사항을 영구적으로 저장
COMMIT;
3. ROLLBACK
💡 ROLLBACK
- 데이터베이스 트랜잭션 내에서 수행한 모든 변경사항을 취소하고 이전 상태로 되돌리는 명령어입니다.
-트랜잭션은 데이터베이스의 일련의 작업을 의미하며, 트랜잭션 내에서 수행한 모든 데이터 변경 작업(INSERT, UPDATE, DELETE 등)은 임시로 보관되고 있습니다. ROLLBACK 명령어를 사용하여 트랜잭션 내에서 수행한 모든 데이터 변경 작업을 취소할 수 있습니다.
- 예를 들어, 특정 데이터를 수정하는 UPDATE 문을 포함하는 트랜잭션을 수행했다고 가정해 봅시다. 이때 트랜잭션 내에서 문제가 발생하여 수정된 데이터가 잘못되었다면, ROLLBACK 명령어를 실행하여 해당 트랜잭션의 모든 변경사항을 취소할 수 있습니다. 이후 데이터베이스는 트랜잭션 이전 상태로 복원되며, 잘못된 수정이 적용되지 않습니다.
-- ROLLBACK: 트랜잭션을 취소하고 변경사항을 이전 상태로 되돌림
ROLLBACK;
3. SAVEPOINT
💡 SAVEPOINT - 데이터베이스 트랜잭션 내에서 특정 지점에 저장점을 설정하는 명령어입니다.
- 저장점은 트랜잭션 내에서 특정 지점으로 돌아가기 위해 사용될 수 있습니다. 이후 ROLLBACK 명령어를 사용하면 설정한 저장점까지 트랜잭션을 되돌릴 수 있습니다.
- 트랜잭션 내에서 중간 단계의 커밋 없이 작업을 분할하고 관리할 수 있는 유용한 기능입니다. - 예를 들어, 트랜잭션 내에서 여러 개의 데이터 수정 작업을 수행하다가 특정 시점에서 문제가 발생했다면, 해당 문제가 발생하기 이전의 저장점으로 트랜잭션을 롤백하고 다른 조치를 취할 수 있습니다.
-- SAVEPOINT: 트랜잭션 내에서 저장점을 설정하여 특정 지점까지만 롤백 가능
SAVEPOINT savepoint_name;
-- SAVEPOINT 사용예시:
SAVEPOINT sp1;
UPDATE table_name
SET column1 = value1
WHERE condition1;
SAVEPOINT sp2;
UPDATE table_name
SET column2 = value2
WHERE condition2;
ROLLBACK TO SAVEPOINT sp1;
4. SET TRANSACTION
💡 SET TRANSACTION - 데이터베이스 트랜잭션의 특성을 설정하는 명령어입니다.
- 트랜잭션은 데이터베이스의 일련의 작업을 의미하며, SET TRANSACTION 명령어를 사용하여 트랜잭션의 격리 수준, 읽기 전용 여부 등을 설정할 수 있습니다.
- 격리 수준은 동시에 여러 트랜잭션이 동작할 때 발생할 수 있는 간섭을 통제하는 방법을 정의하는 데 사용됩니다. 데이터베이스는 일관성, 격리성, 독립성, 지속성 (ACID)을 보장하기 위해 격리 수준을 지원합니다. SET TRANSACTION 명령어를 사용하여 격리 수준을 설정함으로써 다른 트랜잭션과의 상호작용을 제어할 수 있습니다.
- 또한 SET TRANSACTION 명령어를 사용하여 트랜잭션을 읽기 전용으로 지정할 수도 있습니다. 이는 특정 작업을 수행하는 동안 다른 트랜잭션에 의한 변경사항이 발생하지 않도록 보장하는 데 사용됩니다. 읽기 전용 트랜잭션은 데이터의 무결성과 일관성을 유지하기 위해 유용합니다.
💡 사용구조
- SET TRANSACTION를 통해서 트랜잭션의 격리 수준, 잠금 방식 등을 설정할 수 있습니다.
- SET TRANSACTION 문은 트랜잭션의 격리 수준을 SERIALIZABLE, REPEATABLE READ, READ COMMITTED, READ UNCOMMITTED 중에서 선택하여 설정할 수 있습니다.
- 또한, 트랜잭션의 읽기/쓰기 속성을 READ WRITE 또는 READ ONLY 중에서 선택하여 설정할 수 있습니다. 그리고, 트랜잭션의 지연 속성을 DEFERRABLE 또는 NOT DEFERRABLE 중에서 선택하여 설정할 수 있습니다.
SET TRANSACTION [ ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED } ]
[ READ WRITE | READ ONLY ]
[ DEFERRABLE | NOT DEFERRABLE ]
[ [ NOT ] DEFERRED ]
[ [ NOT ] ENFORCED ]
[ [ NOT ] AUTOCOMMIT ]
[ [ NOT ] SNAPSHOT ]
[ [ NOT ] READ ONLY ]
[ [ NOT ] READ WRITE ]
[ [ NOT ] STARTED ]
[ [ NOT ] IN PROGRESS ]
[ [ NOT ] COMMITTED ]
[ [ NOT ] COMMIT ]
[ [ NOT ] ROLLBACK ]
[ [ NOT ] SAVEPOINT ]
[ [ NOT ] WORK ]
[ [ NOT ] TRANSACTION ]
[ [ NOT ] NAME 'transaction_name' ]
[ [ NOT ] ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED } ]
[ [ NOT ] READ WRITE | [ NOT ] READ ONLY ]
[ [ NOT ] DEFERRABLE | [ NOT ] NOT DEFERRABLE ]
[ [ NOT ] DEFERRED | [ NOT ] NOT DEFERRED ]
[ [ NOT ] ENFORCED | [ NOT ] NOT ENFORCED ]
[ [ NOT ] AUTOCOMMIT | [ NOT ] NOT AUTOCOMMIT ]
[ [ NOT ] SNAPSHOT | [ NOT ] NOT SNAPSHOT ]
[ [ NOT ] READ ONLY | [ NOT ] NOT READ ONLY ]
[ [ NOT ] READ WRITE | [ NOT ] NOT READ WRITE ]
[ [ NOT ] STARTED | [ NOT ] NOT STARTED ]
[ [ NOT ] IN PROGRESS | [ NOT ] NOT IN PROGRESS ]
[ [ NOT ] COMMITTED | [ NOT ] NOT COMMITTED ]
[ [ NOT ] COMMIT | [ NOT ] NOT COMMIT ]
[ [ NOT ] ROLLBACK | [ NOT ] NOT ROLLBACK ]
[ [ NOT ] SAVEPOINT | [ NOT ] NOT SAVEPOINT ]
[ [ NOT ] WORK | [ NOT ] NOT WORK ]
[ [ NOT ] TRANSACTION | [ NOT ] NOT TRANSACTION ]
[ [ NOT ] NAME 'transaction_name' ]
💡 사용 예시
- 트랜잭션의 격리 수준을 SERIALIZABLE로 설정하고, 읽기/쓰기 속성을 READ WRITE로 설정하는 SET TRANSACTION 문의 예입니다
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
READ WRITE;