
해당 글에서는 이전에 이해하였던 해시 알고리즘을 기반으로 자주 처리되는 구조나 문제 풀이의 이해를 돕기 위해 작성한 글입니다.

💡 [참고] 해당 글은 이전에 작성한 글에서 이어지는 내용입니다.
[Java/알고리즘] 탐색 알고리즘 : 해시 알고리즘(Hash Algorithm) 이해하기 -1
해당 글에서는 탐색 알고리즘 중 해시 알고리즘에 대해 이해를 돕기 위해 작성한 글입니다. 1) 탐색 알고리즘(Searching Algorithm)💡 탐색 알고리즘(Searching Algorithm) - 데이터 구조 내에서 필요한 정보
adjh54.tistory.com
1) 주요 메서드
1. HashMap
| 메서드 | 리턴 값 | 설명 |
| put(K key, V value) | V | 해시 맵 내에 키와 값을 맵에 추가 및 값 변경 |
| get(Object key) | V | 해시 맵 내에 주어진 키에 해당하는 값을 반환 |
| size() | int | 해시 맵의 요소 개수 값을 반환 |
| entrySet() | Set<Map.Entry<K,V>> | 해시 맵에 있는 모든 키-값 쌍을 반환 |
| containsKey(Object key) | boolean | 해시 맵 내에 주어진 키가 있는지 여부 확인 |
| containsValue(Object value) | boolean | 해시 맵 내에 주어진 값이 있는지 여부 확인 |
| remove(Object key) | V | 해시 맵 내에 주어진 키에 해당하는 키-값 쌍을 삭제 |
| clear() | 없음 | 해시 맵 내에 맵에서 모든 키-값 쌍을 삭제 |
| getOrDefault(Object key, V defaultValue) | V | 해시 맵내에 키 값이 존재 확인 후 defaultValue 값을 반환 |
HashMap (Java SE 11 & JDK 11 )
If the specified key is not already associated with a value (or is mapped to null), attempts to compute its value using the given mapping function and enters it into this map unless null. If the mapping function returns null, no mapping is recorded. If the
docs.oracle.com
2. HashSet
| 메서드 | 리턴 값 | 설명 |
| add(E) | boolean | 지정된 요소가 아직 없는 경우 이 세트에 추가합니다. |
| clear() | void | 이 세트의 모든 요소를 제거합니다. |
| clone() | Object | 이 HashSet 인스턴스의 얕은 복사본을 반환합니다: 요소 자체는 복제되지 않습니다. |
| contains(Object) | boolean | 이 세트가 지정된 요소를 포함하고 있으면 true를 반환합니다. |
| isEmpty() | boolean | 이 세트가 요소를 포함하고 있지 않으면 true를 반환합니다. |
| iterator() | Iterator | 이 세트의 요소에 대한 반복자를 반환합니다. |
| remove(Object) | boolean | 지정된 요소가 있으면 이 세트에서 제거합니다. |
| size() | int | 이 세트의 요소 수(기수)를 반환합니다. |
| spliterator() | Spliterator | 이 세트의 요소에 대해 결합 및 실패-빠른 Spliterator를 생성합니다. |
HashSet (Java SE 11 & JDK 11 )
This class implements the Set interface, backed by a hash table (actually a HashMap instance). It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permi
docs.oracle.com
2) 탐색 알고리즘 > 해시 알고리즘 주요 처리과정
💡 탐색 알고리즘 > 해시 알고리즘 주요 처리과정
- 해시 알고리즘에서는 주로 배열이 주어지며 비 정형 데이터를 해시 알고리즘을 통해서 비슷하거나, 동일한 요소끼리 묶어서 정형화 작업을 수행합니다.
- 이를 통해서 원하는 값을 추출하여 결과값을 얻는 형태로 구성이 됩니다.
1. 문제를 풀기 위한 비정형 데이터(배열)가 주어집니다
💡 문제를 풀기 위한 비정형 데이터(배열)가 주어집니다
- 배열로 구성된 데이터 내에서 동일한 값을 키, 값 형태로 묶거나 혹은 분류하는 구성 작업을 진행함.
// 비 정형 구조 데이터
int[] nums = {3, 1, 2, 3};
String[] participant = {"leo", "kiki", "eden"};
String[] phone_book = {"123", "456", "789"};
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
String[] genres = {"classic", "pop", "classic", "classic", "pop"};
int[] plays = {500, 600, 150, 800, 2500};
String[] orders = {"alex pizza pasta", "alex pizza pizza", "alex noodle", "bob pasta", "bob noodle sandwich pasta", "bob steak noodle"};
2. Map 구성 및 동일하거나 연관된 요소들끼리 묶습니다
💡 Map 구성 및 동일하거나 연관된 요소들끼리 묶습니다
- 위에 배열 형태를 순회하면서 Map으로 구성합니다.
- 주로 Counting을 하거나 동일하거나 혹은 연관된 요소끼리 묶는 작업을 수행합니다.(해시 알고리즘의 key가 중복되지 않는 특성을 이용합니다)
- 해당 작업에서 Counting을 하는 작업의 경우나 합계(Sum)를 수행하는 경우 getOrDefault() 메서드를 활용합니다
/**
* 패턴 1: 동일한 요소끼리 묶어서 Counting을 합니다.
*/
// 1. 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
int[] nums = {3, 1, 2, 3};
Map<Integer, Integer> resultMap = new HashMap<>();
for (int num : nums) {
// [STEP2] 해시 맵 내에 구성할때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
resultMap.put(num, resultMap.getOrDefault(num, 0) + 1);
}
// 2. 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
String[] participant = {"leo", "kiki", "eden"};
Map<String, Integer> pHashMap = new HashMap<>();
for (String participantItem : participant) {
pHashMap.put(participantItem, pHashMap.getOrDefault(participantItem, 0) + 1);
}
// 3. 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
Map<String, Integer> resultMap2 = new HashMap<>();
for (String[] cloth : clothes) {
resultMap2.put(cloth[1], resultMap.getOrDefault(cloth[1], 0) + 1);
}
// 4. 배열 내의 비 정형 데이터를 key-value 형태로 묶어서 요소들을 추가
String[] orders = {"alex pizza pasta", "alex pizza pizza", "alex noodle", "bob pasta", "bob noodle sandwich pasta", "bob steak noodle"};
Map<String, HashSet<String>> map = new HashMap<>();
// [STEP1] 주문 배열을 순회합니다.
for (String order : orders) {
// [STEP2] 주문 배열 중 이름을 추출합니다.
String[] splitOrder = order.split(" ");
String customer = splitOrder[0]; // 고객 이름
// [STEP3] Hashset 내에 값이 존재하는지 확인합니다.
HashSet<String> menuSet = map.get(customer);
// [STEP4] HashSet이 존재하지 않는 경우 : null 값을 넣지 않기 위해 초기화 수행하여 값을 넣지 않습니다.
if (menuSet == null) {
menuSet = new HashSet<>();
map.put(customer, menuSet);
}
// [STEP5] 주문 내용에 대해 HashSet에 중복을 제외하여 주문 내용을 넣습니다.
for (int i = 1; i < splitOrder.length; i++) {
menuSet.add(splitOrder[i]); // 메뉴 추가
}
}
/**
* 패턴2 : 중복이 없는 배열 형태의 HashSet 내의 적재함.
*/
String[] phone_book = {"123", "456", "789"};
HashSet<String> hashSet = new HashSet<>();
for (String phoneBookItem : phone_book) {
hashSet.add(phoneBookItem);
}
3. 구성한 Map을 순회하면서 값을 추출하며 후 처리를 하여 결과값을 추출합니다.
💡 구성한 Map을 순회하면서 값을 추출하며 후처리를 수행하여 결과값을 추출합니다.
- Map에 대한 구성을 수행하면 다시 해당 Map에 대해 순회하며 후처리를 수행하여 결과값을 추출합니다.
- 구성한 Map은 Map.Entry를 통해 감싸서 entrySet() 함수를 통해서 key-value 값을 추출합니다
// 배열 내의 동일한 값을 key-value 형태로 묶어서 Counting
String[] participant = {"leo", "kiki", "eden"};
Map<String, Integer> pHashMap = new HashMap<>();
for (String participantItem : participant) {
pHashMap.put(participantItem, pHashMap.getOrDefault(participantItem, 0) + 1);
}
// Map을 순회하면서 0이 아닌 값을 찾아서 결과로 반환합니다.
for (Map.Entry<String, Integer> entry : pHashMap.entrySet()) {
if (entry.getValue() != 0) {
answer = entry.getKey();
}
}
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
Map<String, Integer> resultMap = new HashMap<>();
for (String[] cloth : clothes) {
resultMap.put(cloth[1], resultMap.getOrDefault(cloth[1], 0) + 1);
}
for (Map.Entry<String, Integer> entry : resultMap.entrySet()) {
answer *= entry.getValue() + 1;
}
int itemCnt = 0;
for (Map.Entry<Integer, Integer> entry : list) {
if (itemCnt < 2) {
itemCnt += 1;
answerList.add(entry.getKey());
System.out.println("itemCnt :: " + itemCnt);
}
}
3) 문제로 이해하기 : 프로그래머스
1. level1 : 폰켓몬
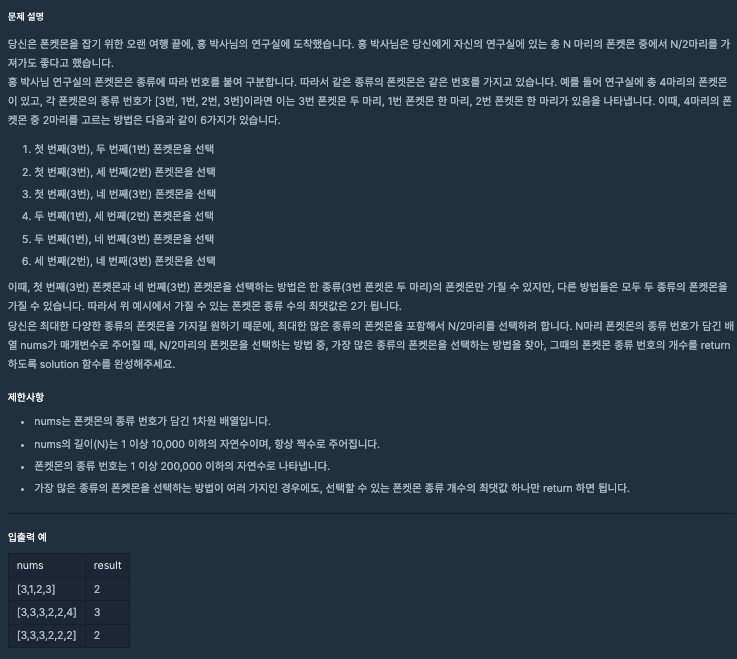
💡 풀이 과정
1. 리스트를 해시 맵으로 폰켓몬 번호 별로 개수를 저장하는 해시 맵을 구성 합니다 : 폰켓몬 번호(key), 폰켓몬 번호 별 개수(value)
2. 해시 맵 내에 구성할 때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
3. 폰켓몬의 종류별 개수와 최대로 얻을 수 있는 폰켓몬 개수를 구합니다.
4. 결과값을 반환합니다.
- 폰켓몬의 종류보다 얻을 수 있는 개수가 많은 경우 => 폰켓몬 종류 반환
- 폰켓몬의 종류보다 얻을 수 있는 개수가 적은 경우 => 얻을 수 있는 개수 반환
/**
* [프로그래머스] Level1 - 폰켓몬
*
* @return
* @link https://school.programmers.co.kr/learn/courses/30/lessons/1845
*/
@PostMapping("/1")
public ResponseEntity<Object> question1() {
int answer = 0;
int[] nums = {3, 1, 2, 3};
int[] nums2 = {3, 1, 2, 3};
int[] nums3 = {3, 1, 2, 3};
// [STEP1] 폰켓몬 번호 별로 갯수를 저장하는 해시 맵을 구성합니다 : 폰켓몬 번호(key), 폰켓몬 번호 별 개수(value)
Map<Integer, Integer> resultMap = new HashMap<>();
for (int num : nums) {
// [STEP2] 해시 맵 내에 구성할때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
resultMap.put(num, resultMap.getOrDefault(num, 0) + 1);
}
System.out.println("resultMap :: " + resultMap); // {1=1, 2=1, 3=2}
// [STEP3] 폰켓몬의 종류 별 개수와 최대로 얻을 수 있는 폰켓몬 개수를 구합니다.
answer = resultMap.size();
int obtainCnt = Math.abs(nums.length / 2);
// [STEP4] 결과값을 반환합니다.
// 1. 폰켓몬의 종류 보다 얻을 수 있는 개수가 많은 경우 => 폰켓몬 종류 반환
// 1. 폰켓몬의 종류 보다 얻을 수 있는 개수가 적은 경우 => 얻을 수 있는 개수 반환
answer = answer < obtainCnt ? answer : obtainCnt;
return new ResponseEntity<>(answer, HttpStatus.OK);
}프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
2. level1 : 완주하지 못한 선수

💡 풀이 과정
1. Map 내에 참가자 목록(participant)을 추가합니다. 참가자 이름(key), 참가여부 체크(value) - 0: 참가, 1: 미 참가
2. 해시 맵 내에 구성할 때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
3. 완주 한 인원을 체크해서 참가여부에 따라 참가여부 체크(value)를 -1로 참가 체크를 수행합니다.
4. Map을 순회하면서 0이 아닌 값을 찾아서 결과로 반환합니다.
/**
* [프로그래머스] Level1 - 완주하지 못한 선수
*
* @return
* @link https://school.programmers.co.kr/learn/courses/30/lessons/42576
*/
@PostMapping("/2")
public ResponseEntity<Object> question2() {
String answer = "";
String[] participant = {"leo", "kiki", "eden"};
String[] completion = {"eden", "kiki"};
Map<String, Integer> pHashMap = new HashMap<>();
// Map 내에 참가자 목록(participant)을 추가합니다. 참가자 이름(key), 참가여부 체크(value) - 0: 참가, 1: 미 참가
for (String participantItem : participant) {
pHashMap.put(participantItem, pHashMap.getOrDefault(participantItem, 0) + 1);
}
// 완주 한 인원을 체크해서 참가여부에 따라 참가여부 체크(value)를 -1로 참가 체크를 수행합니다.
for (String completionItem : completion) {
pHashMap.put(completionItem, pHashMap.get(completionItem) - 1);
}
// Map을 순회하면서 0이 아닌 값을 찾아서 결과로 반환합니다.
for (Map.Entry<String, Integer> entry : pHashMap.entrySet()) {
if (entry.getValue() != 0) {
answer = entry.getKey();
}
}
return new ResponseEntity<>(answer, HttpStatus.OK);
}
3. level2 : 전화번호 목록
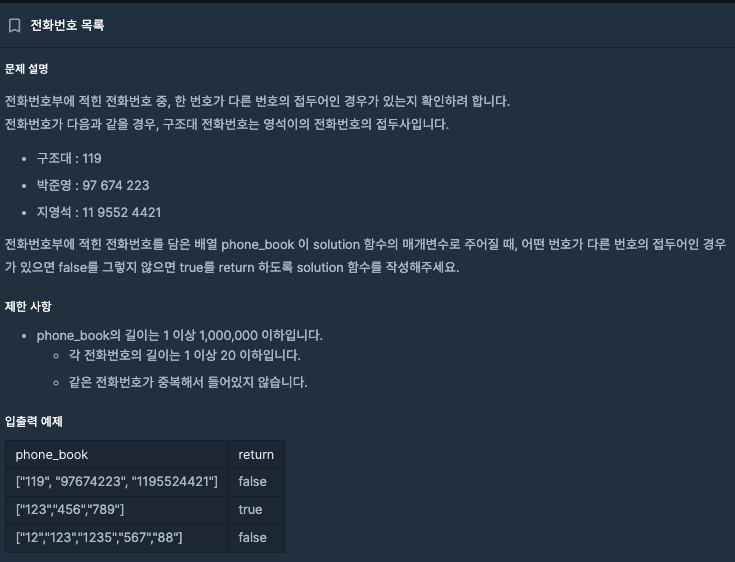
💡 풀이 과정
1. 1차원 배열을 해시 셋으로 구성합니다 : 요소를 해시 셋에 넣습니다.
- 해시 맵을 사용하는 것보다 해시 셋은 해시함수를 통해 중복확인을 하여 빠른 검색을 수행합니다.
2. 리스트를 전체 순회하여 요소를 출력합니다.
3. 요소의 길이만큼 순회합니다. : 단어 출력
4. 해시맵의 값과 단어를 하나씩 쪼개가며 접두사를 비교합니다 : 같을 경우 false 값 반환
- phone_book의 첫 번째에서 시작하여 하나씩 접두사를 비교하며 결과값을 확인합니다.
/**
* [프로그래머스] level2 - 전화번호 목록
*
* @return
* @link <https://school.programmers.co.kr/learn/courses/30/lessons/42577>
*/
@PostMapping("/3")
public ResponseEntity question3() {
boolean answer = true;
// String[] phone_book = {"119", "97674223", "1195524421"};
String[] phone_book = {"123", "456", "789"};
// [STEP1] 리스트트 해시 셋으로 구성합니다 : 요소를 해시 셋에 넣습니다.
// 해시 맵을 사용하는것보다 해시셋은 해시함수를 통해 중복확인을 하여 빠른 검색을 수행합니다.
HashSet hashSet = new HashSet<>();
for (String phoneBookItem : phone_book) {
hashSet.add(phoneBookItem);
}
System.out.println("hashset :: " + hashSet); // [123, 456, 789]
// [STEP2] 리스트를 전체 순회하여 요소를 출력 합니다
for (String phoneBookItem : phone_book) {
// [STEP3] 요소의 길이만큼 순회합니다. : 단어 출력
for (int j = 0; j < phoneBookItem.length(); j++) {
// [STEP4] 해시맵의 값과 단어를 하나씩 쪼개가며 접두사를 비교합니다 : 같을 경우 false 값 반환
if (hashSet.contains(phoneBookItem.substring(0, j))) {
answer = false;
break;
}
}
}
return new ResponseEntity<>(answer, HttpStatus.OK);
}
4. level2 : 의상
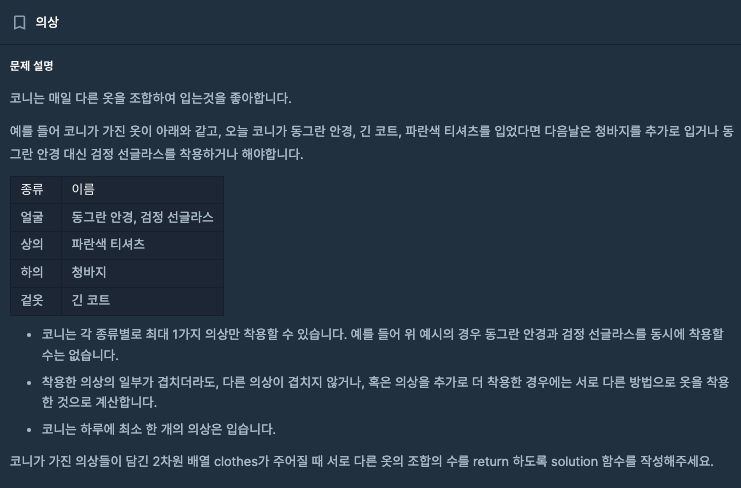
💡 문제 풀이
1. 2차원 배열을 HashMap 형태로 구성합니다 : 옷 종류(key), 옷 개수(Value)
- 옷 종류 별로 개수를 구하기 위해 HashMap을 구성합니다.
2. 해시 맵을 구성할 때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
- 옷 종류 별로 개수를 세기 위해서 해당 메서드를 활용합니다.
3. 해시 맵을 순회 합니다.
- 구성한 해시 맵을 순회 합니다.
4. 값에 1을 더하여 누적하여 곱해줍니다. : 중복되지 않는 키(옷 종류)의 합
- 안경이 1개인 경우 1을 더해서 2를 만들고, 모자의 경우 2개가 되어 1을 더하고 3을 만들고 곱해줍니다.
5. 아무것도 입지 않은 경우를 제외합니다.
- 최종 결과값에서 1을 뺀 결과를 반환합니다.
/**
* [프로그래머스] level2 : 의상
*
* @return
* @link https://school.programmers.co.kr/learn/courses/30/lessons/42578
*/
@PostMapping("/4")
public ResponseEntity<Object> question4() {
int answer = 1;
String[][] clothes = {{"yellow_hat", "headgear"}, {"blue_sunglasses", "eyewear"}, {"green_turban", "headgear"}};
// [STEP1] 2차원 배열을 HashMap 형태로 구성합니다 : 옷 종류(key), 옷 개수(Value)
Map<String, Integer> resultMap = new HashMap<>();
for (String[] cloth : clothes) {
// [STEP2] 해시 맵을 구성할때, 동일한 키 값이 존재하면(getOrDefault) 값을 1 더 해줍니다.
resultMap.put(cloth[1], resultMap.getOrDefault(cloth[1], 0) + 1);
}
System.out.println("resultMap :: " + resultMap); // resultMap :: {eyewear=1, headgear=2}
// [STEP3] 해시 맵을 순회합니다.
for (Map.Entry<String, Integer> entry : resultMap.entrySet()) {
// [STEP4] 값에 1을 더하여 누적하여 곱해줍니다. : 중복되지 않는 키(옷 종류)의 합
answer *= entry.getValue() + 1;
}
// [STEP5] 아무것도 입지 않은 경우를 제외합니다.
answer -= 1;
return new ResponseEntity<>(answer, HttpStatus.OK);
}
5. level3: 베스트 앨범
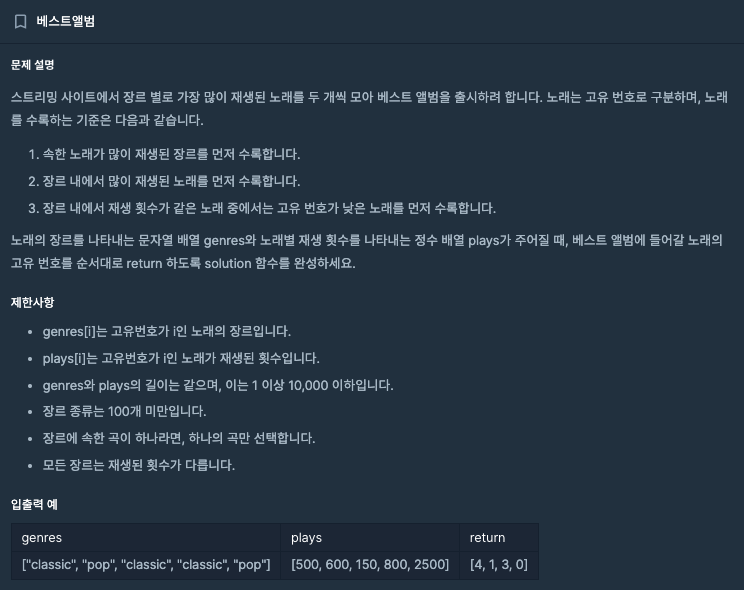
💡 베스트 앨범 풀이 과정
1. 배열을 해시 맵으로 변환합니다.
- Array to HashMap
2. 장르 별(genres) 플레이(plays) 횟수의 합을 요소로 추가합니다. : 동일한 장르를 묶어서 합합니다.
- 노래가 가장 많이 재생된 장르를 먼저 수록하기 때문에 장르 별 플레이 횟수를 합을 구합니다.
3. 장르 별(genres) 플레이(plays) 합이 큰 순서(내림차순)로 정렬합니다.
- 구해진 합을 기반으로 ‘플레이 횟수’가 가장 많은 장르를 구하기 위해 정렬합니다.
4. 플레이 합이 큰 리스트 순서대로 순회합니다.
- 우선순위로 해당 장르를 수록하기 위해서 순회합니다.
5. 해시 맵 내에 인덱스(key), 플레이(play)를 저장합니다. : 이를 통해 장르 별 순서를 정합니다.
- 구성한 리스트 내에서는 가장 플레이가 많이 된 내용에 대해서만 순차적으로 배열로 들어가 있기에 해당 값을 기반으로 장르의 인덱스(key), 플레이(play)를 저장합니다.
6. 장르 별 순서 맵을 리스트로 변환하여 플레이 값(value)에 따라 정렬을 수행합니다.
- 장르의 값 별로 정렬을 수행합니다.
7. 정렬된 리스트를 풀어 순서대로 값을 가져와 리스트에 담아서 최종 index를 구성합니다. (최대 장르별 2건만 들어갈 수 있음)
- 정렬된 장르를 기반으로 순회하며, 2곡에 대해서만 수록하기에 해당 값만을 리스트에 넣습니다.
8. 리스트를 배열로 구성하여 최종 결과값을 출력합니다.
- 리스트를 다시 배열로 구성하여 최종 반환을 수행합니다.
/**
* [프로그래머스] level3 : 베스트 앨범
*
* @return
* @link https://school.programmers.co.kr/learn/courses/30/lessons/42579
*/
@PostMapping("/5")
public ResponseEntity<Object> question5() {
String[] genres = {"classic", "pop", "classic", "classic", "pop"};
int[] plays = {500, 600, 150, 800, 2500};
List<Integer> answerList = new ArrayList<>();
// [STEP1] 배열을 해시 맵으로 변환합니다.
Map<String, Integer> totalGenresMap = new HashMap<>();
for (int i = 0; i < genres.length; i++) {
// [STEP2] 장르 별(genres) 플레이(plays) 횟수의 합을 요소로 추가합니다. : 동일한 장르를 묶어서 합합니다.
totalGenresMap.put(genres[i], totalGenresMap.getOrDefault(genres[i], 0) + plays[i]);
}
System.out.println("totalGenresMap :: " + totalGenresMap); // {pop=3100, classic=1450}
// [STEP3] 장르 별(genres) 플레이(plays) 합이 큰 순서(내림차순)로 정렬 합니다.
List<String> sortedList = new ArrayList<>(totalGenresMap.keySet());
Collections.sort(sortedList, (v1, v2) -> totalGenresMap.get(v2).compareTo(totalGenresMap.get(v1)));
System.out.println("정렬 리스트 :" + sortedList); // ["pop", "classic"]
// [STEP4] 플레이 합이 큰 리스트 순서대로 순회 합니다.
for (String listItem : sortedList) {
// [STEP5] 맵 내에 인덱스(key), 플레이(play)를 저장합니다. : 이를 통해 장르 별 순서를 정합니다.
Map<Integer, Integer> genresMap = new HashMap<>();
for (int i = 0; i < genres.length; i++) {
if (listItem.equals(genres[i])) {
genresMap.put(i, plays[i]);
}
}
System.out.println("genresMap :: " + genresMap); // {1=600, 4=2500}, {0=500, 2=150, 3=800}
// [STEP6] 장르 별 순서 맵을 리스트로 변환하여 플레이 값(value)에 따라 정렬을 수행합니다.
List<Map.Entry<Integer, Integer>> list = new ArrayList<>(genresMap.entrySet());
list.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));
System.out.println("list ::" + list); // [4=2500, 1=600], [3=800, 0=500, 2=150]
// [STEP7] 정렬된 리스트를 풀어 순서대로 값을 가져와 리스트에 담아서 최종 index를 구성합니다. (최대 장르별 2건만 들어갈 수 있음)
int itemCnt = 0;
for (Map.Entry<Integer, Integer> entry : list) {
if (itemCnt < 2) {
itemCnt += 1;
answerList.add(entry.getKey());
System.out.println("itemCnt :: " + itemCnt);
}
}
}
// [STEP8] 리스트를 배열로 구성하여 최종 결과값을 출력합니다.
int[] answer = new int[answerList.size()];
for (int i = 0; i < answerList.size(); i++) answer[i] = answerList.get(i);
return new ResponseEntity<>(answer, HttpStatus.OK);
}
💡 [참고] 해당 코드는 아래 Git Repository에서 확인이 가능합니다.
blog-codes/java-algorithm at main · adjh54ir/blog-codes
Contributor9 티스토리 블로그 내에서 활용한 내용들을 담은 레포지토리입니다. Contribute to adjh54ir/blog-codes development by creating an account on GitHub.
github.com
오늘도 감사합니다. 😀
'Java > 알고리즘 & 자료구조' 카테고리의 다른 글
| [Java/알고리즘] 탐색 알고리즘 : 해시 알고리즘(Hash Algorithm) 이해하기 -1 (0) | 2024.05.19 |
|---|---|
| [Java/알고리즘] 투 포인터 알고리즘(Two Pointer Algorithm) 이해하기 -2: 문제로 이해하기 (3) | 2024.01.21 |
| [Java/알고리즘] 투 포인터 알고리즘(Two Pointer Algorithm) 이해하기 -1 : 종류, 활용방안 (1) | 2024.01.09 |
| [Java/알고리즘] 정렬 알고리즘(Sort Algorithm) 이해하기 -1 : 기본 구조 및 종류 (1) | 2023.12.02 |
| [Java/알고리즘] 깊이 우선 탐색(DFS) / 너비 우선 탐색(BFS) 이해하기 -1 : 이론 및 구조 (3) | 2023.11.26 |