
해당 글에서는 Spring WebFlux 환경에서 R2DBC를 이용하여서 데이터베이스에 접근하고 활용하는 방법에 대해 알아봅니다.


💡 [참고] 반응형 프로그래밍을 구현하기 위해 Spring WebFlux에 대해 궁금하시면 아래의 글을 참고하시면 도움이 됩니다.
| 분류 | 링크 |
| Spring Boot Webflux 이해하기 -1 : 흐름 및 주요 특징 이해 | https://adjh54.tistory.com/232 |
| Spring Boot Webflux 이해하기 -2 : 활용하기 | https://adjh54.tistory.com/233 |
| Spring Boot WebFlux 이해하고 구현하기 -1 : 반응형 프로그래밍에서 WebFlux까지 흐름 | https://adjh54.tistory.com/627 |
| Spring Boot WebFlux 활용하여 구현하기 -2: 계층구조 및 활용예시 | https://adjh54.tistory.com/628 |
| Spring Boot WebFlux 활용하여 구현하기 -3: Publisher/Subscriber 데이터 처리 타입, 에러 핸들러, 백프레셔 | https://adjh54.tistory.com/629 |
| Spring Boot Data R2DBC 이해하기 -1 : 처리과정 및 환경구성 방법 | https://adjh54.tistory.com/631 |
| Spring Boot WebFlux 활용 Github | https://github.com/adjh54ir/blog-codes/tree/main/spring-boot-webflux |
1) R2DBC (Reactive Relational Database Connectivity)
💡 R2DBC (Reactive Relational Database Connectivity)
- 반응형 프로그래밍(Reactive Programming)에서 관계형 데이터베이스에 접근하기 위한 Reactive Stream 사양(Specification)을 의미합니다.
- 비 차단(Non-Blocking) 방식을 통해 비동기적 데이터베이스 액세스를 지원하도록 특별 설계가 되었습니다.
- 각 데이터베이스 벤더(PostgreSQL, MySQL 등)는 이 사양을 구현한 R2DBC 드라이버를 제공합니다. 예를 들어서, PostgreSQL을 사용할 때는 'r2dbc-postgresql' 드라이버를 사용합니다.
Spring Data R2DBC
Spring Data R2DBC, part of the larger Spring Data family, makes it easy to implement R2DBC based repositories. R2DBC stands for Reactive Relational Database Connectivity, a specification to integrate SQL databases using reactive drivers. Spring Data R2DBC
spring.io
R2DBC
R2DBC 0.8.1.RELEASE: A standard API for reactive programming using SQL databases.
r2dbc.io
1. R2DBC의 주요 특징
| 특징 | 설명 |
| Non-blocking 드라이버 | 비동기적 데이터베이스 액세스를 제공하며, 스레드 블로킹 없이 효율적인 리소스 사용이 가능 |
| 리액티브 스트림 | 백프레셔 메커니즘이 내장되어 있어 데이터 스트림의 효율적인 처리와 제어가 가능 |
| 높은 확장성 | 적은 리소스로 많은 동시 연결 처리가 가능하며, 메모리 사용이 최적화됨 |
| Spring WebFlux 통합 | Spring WebFlux와 완벽한 통합으로 end-to-end 리액티브 애플리케이션 구축 가능 |
| 비동기 프로그래밍 | 전체 스택에서 일관된 비동기 프로그래밍 모델을 제공 |
[ 더 알아보기 ]
💡 백프레셔(Backpressure)
- 데이터 스트림에서 데이터 발행자(Publisher)와 구독자(Subscriber) 사이의 데이터 처리 속도 차이를 조절하기 위한 메커니즘입니다.
- 아래의 예시와 같이 데이터 발행자(Publisher)가 데이터를 데이터 구독자(Subscriber)에게 전달(emit)을 하는 경우 발행자의 데이터 속도가 구독자 속도보다 빠를 때 발생하는 문제에 대해서 백프레셔가 이를 속도를 조절하여 처리합니다.
이는 구독자가 처리할 수 있는 만큼의 데이터만 요청하여 시스템 과부하를 방지하며 메모리의 사용량을 효율적으로 관리하고 시스템의 안정성을 보장합니다.
2. R2DBC 구성요소
💡 R2DBC 구성요소
- R2DBC를 이용하기 위해서는 R2DBC Driver와 Spring Data R2DBC를 사용합니다.
1. R2DBC Driver
- R2DBC SPI에서 정의한 인터페이스들의 구현체입니다. 이는 각 관계형 데이터베이스(PostgreSQL, MySQL 등)에 맞는 특성을 구현체를 구현하며, 데이터베이스와의 실제 통신을 수행합니다.
2. R2DBC SPI
- 관계형 데이터베이스에 접근하여 쿼리를 수행하기 위한 필수 구성요소인 ConnectionFactory, Connection, Statement, Result 구성 요소를 정의한 인터페이스의 집합입니다.
- ConnectionFactory: 데이터베이스 연결을 생성하고 관리하는 인터페이스를 제공합니다.
- Connection: 생성된 연결을 통해 데이터베이스 세션을 관리하고 트랜잭션을 제어합니다.
- Statement: SQL 쿼리를 실행하고 필요한 파라미터를 바인딩하는 역할을 수행합니다.
- Result: 실행된 쿼리의 결과를 처리하고 적절한 형태로 매핑하는 기능을 제공합니다.
3. Spring Data R2DBC
- 관계형 데이터베이스를 동작하기 위한 트랜잭션 및 쿼리를 관리하며 Spring Framework 내에서 메서드 형태로 제공을 합니다.
| 구분 | R2DBC Driver | R2DBC SPI | Spring Data R2DBC |
| 정의 | 데이터베이스와의 실제 통신을 담당하는 드라이버 | R2DBC 드라이버와 클라이언트 간의 인터페이스 정의 | Spring 프레임워크에서 R2DBC를 쉽게 사용할 수 있게 해주는 추상화 계층 |
| 주요 기능 | - DB 연결 관리 - SQL 실행 - 리액티브 스트림 지원 |
- 표준 API 정의 - 드라이버 구현 가이드라인 - 공통 인터페이스 제공 |
- Repository 추상화 - 객체 매핑 - 트랜잭션 관리 |
| 사용 예시 | PostgreSQL, MySQL, H2 등의 구체적인 드라이버 구현체 | Connection, Statement 등의 핵심 인터페이스 | ReactiveCrudRepository 구현 및 사용 |

[ 더 알아보기 ]
💡 추상화 계층(Abstraction Layer)
- 복잡한 하위 시스템이나 기능들을 감추고 더 단순하고 일관된 인터페이스를 제공하는 소프트웨어 계층을 의미합니다.
- 개발자가 복잡한 세부 구현 사항을 알 필요 없이 간단한 인터페이스만으로 시스템을 사용할 수 있게 해 줍니다.
💡 R2DBC를 이용하는 경우 SQL Mapper(MyBatis)와 함께 사용할 수 있는가?
- MyBatis와 직접적인 통합을 지원하지 않습니다. 이는 MyBatis가 blocking I/O 기반의 JDBC에 종속되어 있기 때문입니다. 그렇기에 Spirng Data R2DBC의 네이티브 쿼리 기능을 활용하여 처리를 수행해야 합니다.
💡 R2DBC를 이용하는 경우 JPA와 함께 사용할 수 있는가?
- JPA는 blocking I/O 기반으로 동작하여 R2DBC의 non-blocking 이점을 상쇄시킵니다. 또한 JPA의 영속성 컨텍스트와 R2DBC의 리액티브 모델이 서로 충돌할 수 있습니다
3. R2DBC 구성요소 간의 처리 과정
💡 R2DBC 구성요소간의 처리 과정
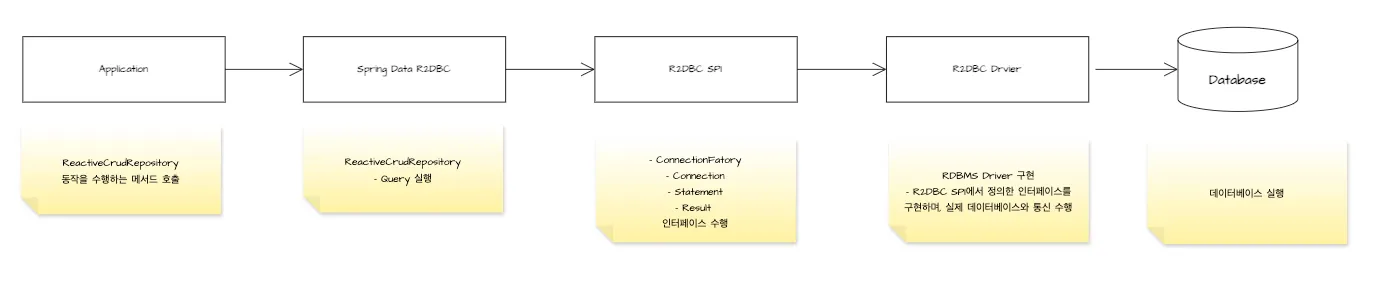
1. 애플리케이션 → Spring Data R2DBC
- 개발자는 Spring Data R2DBC의 ReactiveCrudRepository 인터페이스를 통해 데이터베이스 작업을 수행합니다.
- Spring Data R2DBC는 높은 수준의 추상화를 제공하여 개발자가 쉽게 데이터베이스 작업을 할 수 있게 합니다.
2. Spring Data R2DBC → R2DBC SPI
- Spring Data R2DBC는 내부적으로 R2DBC SPI의 표준 인터페이스를 사용합니다.
- R2DBC SPI는 ConnectionFactory, Connection, Statement, Result 등의 핵심 인터페이스를 정의합니다.
3. R2DBC SPI → R2DBC Driver
- 데이터베이스 드라이버는 R2DBC SPI에서 정의한 인터페이스들을 실제로 구현합니다.
- 각 데이터베이스(PostgreSQL, MySQL 등)에 맞는 구체적인 구현을 제공합니다.
4. R2DBC Driver → Database
- 드라이버는 최종적으로 실제 데이터베이스와 비동기적으로 통신합니다.
- 데이터베이스별 프로토콜을 처리하고 데이터를 변환합니다.
4. R2DBC를 지원하는 데이터베이스 드라이버
💡 R2DBC를 지원하는 데이터베이스 드라이버
- 데이터베이스 드라이버는 애플리케이션과 데이터베이스 간의 통신을 가능하게 해주는 소프트웨어 구성요소를 의미합니다.
- 관계형 데이터베이스 내에서 R2DBC를 지원하는 데이터베이스 드라이버에 대해 확인을 해봅니다.
| 데이터베이스 | R2DBC 드라이버 명 | 관련 링크 |
| Oracle | oracle-r2dbc | https://github.com/oracle/oracle-r2dbc |
| H2 | r2dbc-h2 | https://github.com/r2dbc/r2dbc-h2 |
| MariaDB | r2dbc-mariadb | https://github.com/mariadb-corporation/mariadb-connector-r2dbc |
| MySQL | r2dbc-mysql | https://github.com/asyncer-io/r2dbc-mysql |
| PostgreSQL | r2dbc-postgresql | https://github.com/pgjdbc/r2dbc-postgresql |
| MSSQL | r2dbc-mssql | https://github.com/r2dbc/r2dbc-mssql |
💡 [참고] 아래의 공식 사이트 Driver를 확인하시면 이외에 지원하는 데이터베이스 드라이버를 확인할 수 있습니다.
R2DBC
R2DBC 0.8.1.RELEASE: A standard API for reactive programming using SQL databases.
r2dbc.io
5. R2DBC 내부적 처리과정
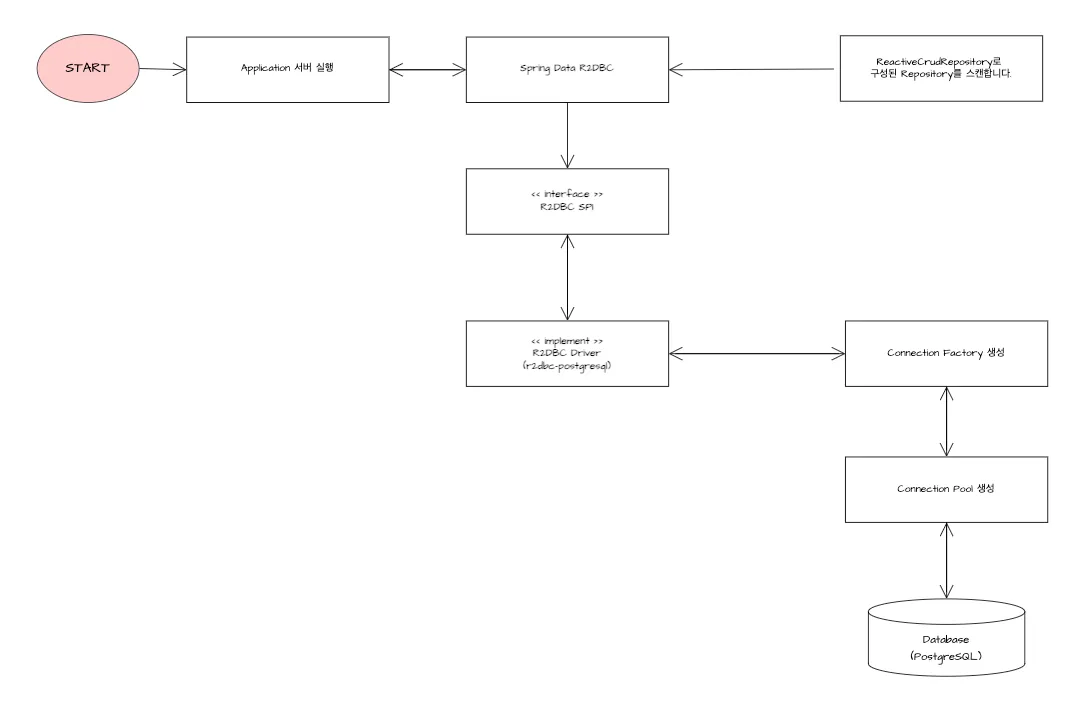
5.1. 데이터베이스 연결 과정
💡 데이터베이스 연결 과정
- 애플리케이션이 실행될 때, 데이터베이스를 연결하는 과정에 대해 알아봅니다.
1. 애플리케이션 실행
- Spring Boot Application이 실행이 되면서 R2DBC 관련 설정 정보를 application.properties/yml 파일 내에서 정보를 읽어옵니다.
2. Spring Boot Data는 ReactiveCrudRepository Repository를 스캔합니다.
- 애플리케이션이 실행되고 Data R2DBC로 구성한 Repository를 스캔합니다.
3. R2DBC SPI(Service Provider Interface)
- ServiceLoader 메커니즘을 통해 R2DBC 드라이버 구현체를 검색하여 필요한 인터페이스(ConnectionFactory, Connection 등)를 준비합니다.
4. R2DBC Drvier 로드(r2dbc-postgresql)
- 특정 데이터베이스에 맞는 R2DBC 드라이버가 로드됩니다.
- 예를 들어, 관계형 데이터베이스로 PostgreSQL을 사용하는 경우, r2dbc-postgresql 드라이버 초기화합니다.
5. ConnectionFactory 초기화
- 데이터베이스 연결을 관리할 ConnectionFactory 인스턴스 생성하고 연결 설정(timeout, SSL 등) 구성합니다.
6. Connection Pool 생성
- 초기 Connection Pool 설정(최소/최대 연결 수 등)합니다.
7. Database 연결 준비
- 실제 데이터베이스와의 연결 채널 확립 및 연결 테스트 수행 및 준비 상태 확인합니다.
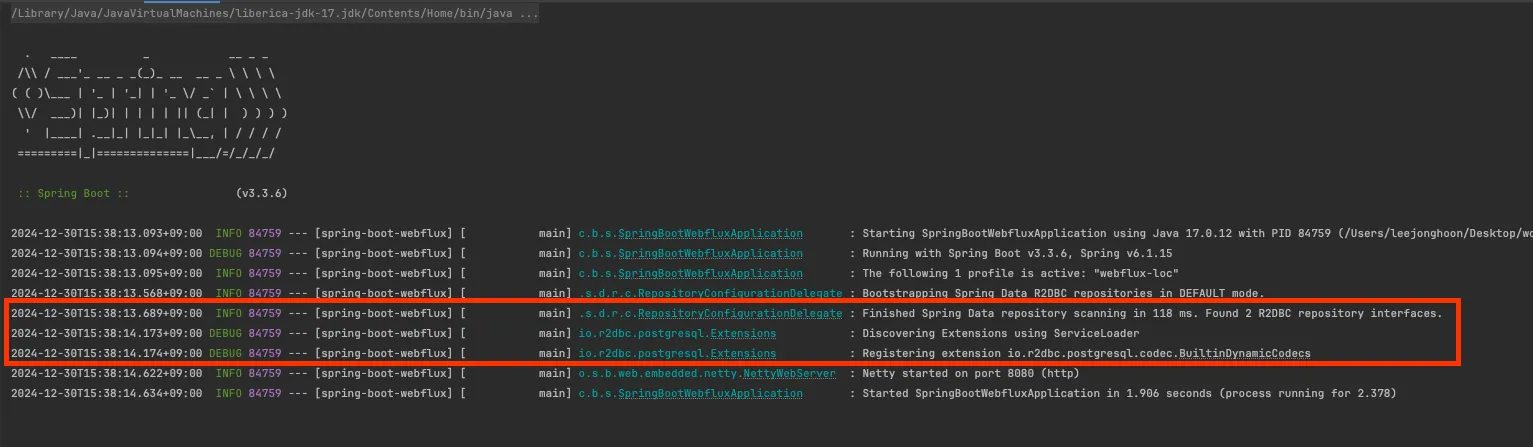
💡 아래와 같이 애플리케이션이 실행하면
1. Finished Spring Data repository scanning in 118 ms. Found 2 R2DBC repository interfaces.
- Spring Boot Data R2DBC의 ReactiveCrudRepository를 통해 구성한 Repository를 스캔하였습니다.
2. io.r2 dbc.postgresql.Extensions : Discovering Extensions using ServiceLoader
- PostgreSQL R2DBC 드라이버가 ServiceLoader를 통해 확장 기능들을 찾는 과정입니다. Java의 SPI(Service Provider Interface) 메커니즘을 사용하여 자동으로 확장 기능을 발견합니다.
3. io.r2dbc.postgresql.Extensions : Registering extension io.r2dbc.postgresql.codec.BuiltinDynamicCodecs
- PostgreSQL의 데이터 타입을 Java 객체로 변환하는 코덱(Codec)을 등록하는 과정입니다.
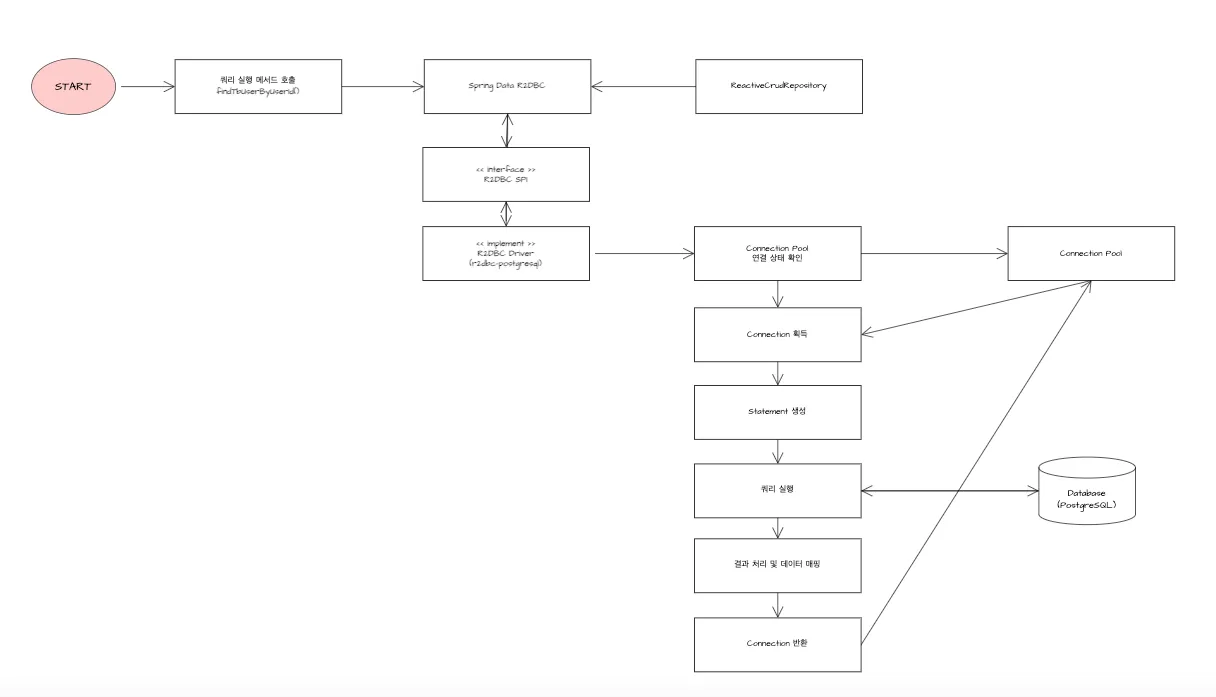
5.2. 쿼리 실행 과정
💡 쿼리 실행 과정
사전 데이터베이- 스가 연결되어 Connection Factory에 Connection Pool이 생성이 되고, 커넥션 풀에서 연결을 획득하여 쿼리 실행, 결과 처리, 트랜잭션 완료 단계로 순차적으로 진행이 됩니다.
💡 연결 준비 단계
1. 쿼리 실행 메서드 호출
- 애플리케이션 서버가 실행되었을 때, 쿼리를 실행하는 메서드를 호출하여 동작을 시작합니다.
2. Spring Boot Data R2DBC의 ReactiveCrudRepository
- ReactiveCrudRepository을 상속받은 Repository 내에서 쿼리를 생성하고 호출합니다.
3. R2DBC SPI(Service Provider Interface)
- Statement, Result 등의 표준 인터페이스를 제공하여 일관된 쿼리 실행 방식 보장데이터베이스 벤더별 구현체들이 이 인터페이스를 따르도록 함
4. R2DBC Driver
- 실제 데이터베이스와의 통신을 담당하는 구현체입니다.
각 데이터베이스 벤더(PostgreSQL, MySQL 등) 별로 R2DBC 사양을 구현한 드라이버를 제공합니다.
- Statement, Result 등의 표준 인터페이스를 구현하여 실제 데이터베이스와의 통신을 처리합니다
💡 실제 실행 단계
1. Connection Pool 연결 상태 확인
- 애플리케이션 실행 시, 생성된 Connection의 여부를 확인합니다.
- 사용 중인 Connection과 실행 중인 Conncetion의 확인을 통해서 존재하지 않을 때, 지정한 Connection Pool 크기 제한 내에서 새로운 Connection을 생성합니다.
2. Connection 획득
- Pool에서 사용 가능한 Connection을 비동기적으로 가져옵니다. 이는 Mono <Connection> 형태로 반환됩니다
3. Statement 생성
- Connection.createStatement()를 통해 Statement 객체를 생성합니다 SQL 쿼리 텍스트를 설정합니다. 필요한 경우 bind() 메서드로 파라미터를 설정합니다.
4. 쿼리 실행
- execute() 메서드를 호출하여 쿼리를 실행합니다.
- 결과는 Publisher <Result> 형태의 스트림으로 반환됩니다
💡 결과 처리 단계
1. 결과 처리 및 매핑
- Result.map()을 사용하여 도메인 객체로 매핑합니다 데이터를 스트림 형태로 처리합니다
2. Connection 반환
- 작업이 완료되면 Connection이 Pool에 자동으로 반환됩니다 close() 메서드를 직접 호출할 필요 없이 자동으로 처리됩니다
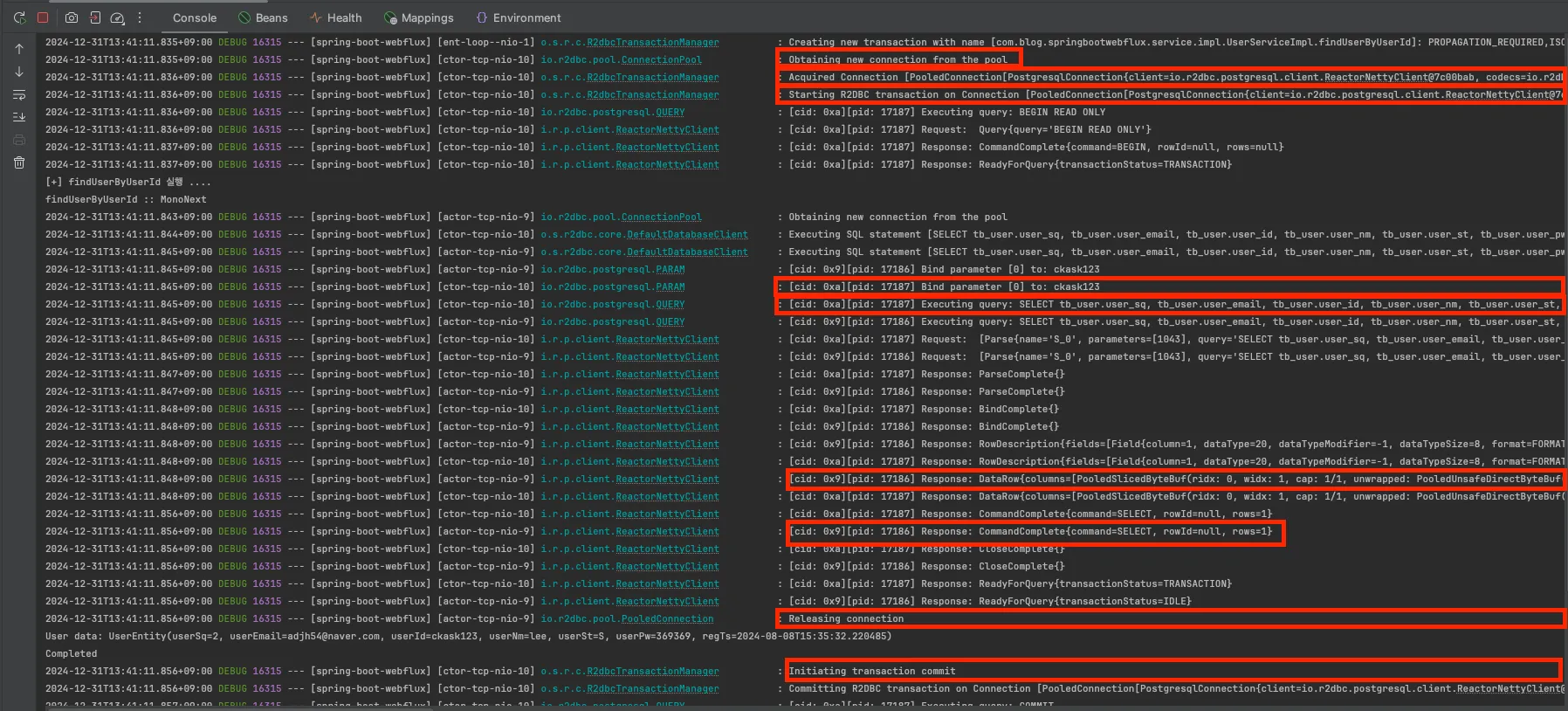
💡 아래와 같이 애플리케이션의 쿼리를 실행하면
💡 실제 실행 단계
1. 커넥션 풀에서 새로운 연결 획득
- io.r2dbc.pool.ConnectionPool : Obtaining new connection from the pool.
- 서버 실행 시 사전에 구성되었던 커넥션 풀로부터 새로운 연결(Connection)을 획득합니다.
2. 커넥션 획득
- o.s.r.c.R2dbcTransactionManager : Acquired Connection쿼리를 실행하기 위한 커넥션을 획득하였습니다.
3. 트랜잭션 시작
- o.s.r.c.R2dbcTransactionManager : Starting R2DBC transaction on Connection
- 커넥션을 통해 트랜잭션이 시작되었습니다.
4. SQL statement
- o.s.r2dbc.core.DefaultDatabaseClient : Executing SQL statement
- 트랜잭션에 수행할 SQL statement가 실행이 됩니다.
5. 파라미터 바인딩
- io.r2 dbc.postgresql.PARAM : "Bind parameter [0] to: ckask123"
- 쿼리 내에 파라미터를 바인딩하여 수행합니다.
6. 쿼리 실행
- io.r2 dbc.postgresql.QUERY - Executing queryPostgreSQL QUERY
- 로그를 통해 실제 쿼리 실행
- ReactorNettyClient를 통한 요청 처리
💡 결과 처리 단계
1. 결과 처리 확인
- i.r.p.client.ReactorNettyClient - Response: RowDescription, Response: DataRowRow
- Description을 통해 결과 컬럼 정보 수신 DataRow를 통해 실제 데이터 수신
2. 트랜잭션 완료 및 연결 반환
- CommandComplete {command=SELECT, rowId=null, rows=1}"Releasing connection"
- 사용한 커넥션을 풀에 반환"Initiating transaction commit" - 트랜잭션 커밋 수행
3. 커넥션 반환
- io.r2dbc.pool.PooledConnection : Releasing connection
- 사용된 커넥션에 대해서는 반환을 받습니다.
💡 [참고] JDBC의 내부적인 처리과정
[Java] JDBC, DBCP, JNDI 이해하기 : 주요기능, 처리과정
해당 글에서는 JDBC, JNDI, DBCP에 대해 이해를 돕기 위해 작성한 글입니다. 1) JDBC(Java Database Connectivity)💡 JDBC(Java Database Connectivity) - 자바에서 데이터베이스에 접근할 수 있도록 해주는 API를 의미합
adjh54.tistory.com
[ 더 알아보기 ]
💡 내부적으로 처리되는 과정이 JDBC 처리과정이랑 비슷한데 다른 점은 뭐야?
- 비동기 처리: R2DBC는 비동기-논블로킹 방식으로 데이터베이스 작업을 수행하며, Publisher 객체를 통해 비동기적으로 쿼리를 실행합니다. 반면 JDBC는 동기-블로킹 방식으로 동작합니다.
- 데이터 처리 방식: R2DBC는 Reactive Streams API를 사용하여 스트림 형태로 데이터를 처리하고, JDBC는 일괄 처리 방식을 사용합니다.
- 리소스 관리: R2DBC는 자동 리소스 관리를 제공하는 반면, JDBC는 수동으로 리소스를 관리해야 합니다.
- 백프레셔: R2DBC는 Publisher와 Subscriber 간의 백프레셔를 통해 데이터 흐름을 제어할 수 있지만, JDBC는 이를 지원하지 않습니다.
5. R2DBC vs JDBC
💡 R2DBC vs JDBC
- 반응형 프로그래밍(Reactive Programming)을 구현하기 위해서 R2DBC를 이용하는 API 사양과 명령형 프로그래밍을 구현하기 위한 JDBC 간의 차이점에 대해 알아봅니다.
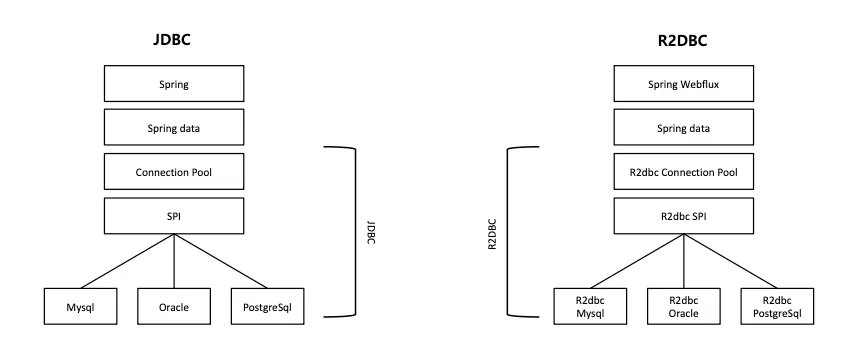
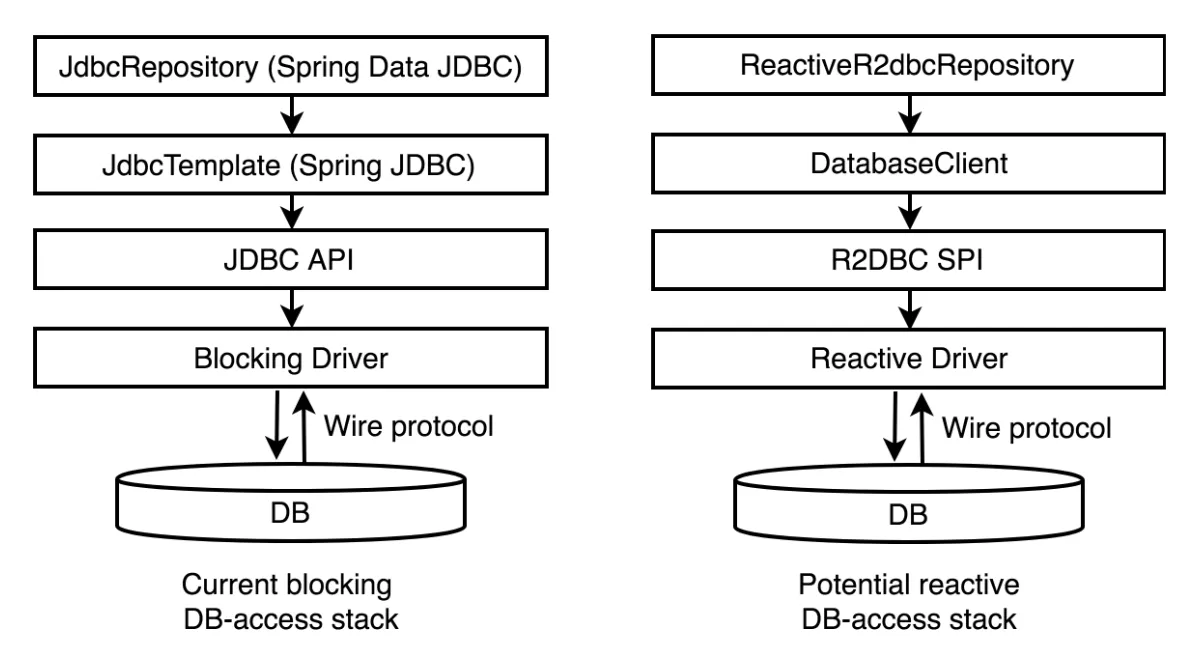
| 특성 | R2DBC | JDBC |
| 실행 모델 | 비동기(Non-blocking) | 동기(Blocking) |
| 데이터 처리 | 스트림 형태의 데이터 처리 | 일괄 처리 방식 |
| 스케일링 | 효율적인 리소스 사용으로 높은 확장성 | 스레드 풀 크기에 제한 |
| 프로그래밍 모델 | 리액티브 | 명령형 |
| 백프레셔 | 지원 | 미지원 |
| 리소스 관리 | 자동 리소스 관리 | 수동 리소스 관리 필요 |
| 연결 방식 | r2dbc: 프로토콜 | jdbc: 프로토콜 |
| 트랜잭션 처리 | 리액티브 트랜잭션 | 동기식 트랜잭션 |
💡 R2DBC를 적용할 때의 주의 사항
- R2DBC는 Spring WebFlux와 함께 사용할 때 가장 큰 장점을 발휘하며, 높은 동시성이 요구되는 애플리케이션에서 특히 유용합니다.
| 주의사항 | 설명 |
| 데이터베이스 지원 | 모든 데이터베이스가 R2DBC를 지원하지는 않음 |
| 마이그레이션 | 기존 JDBC 기반 코드의 마이그레이션이 필요 |
| 학습 곡선 | 리액티브 프로그래밍에 대한 이해가 필요 |
| 디버깅 | 디버깅이 상대적으로 복잡할 수 있음 |
[ 더 알아보기 ]
💡 동시성(Concurrency)이란?
- 여러 작업이 동시에 실행되는 것처럼 보이는 것을 의미합니다. 실제로는 매우 빠른 속도로 작업들 사이를 전환하면서 처리합니다.
2) Spring Boot Data R2DBC
💡Spring Boot Data R2DBC
- Spring Framework에서 제공하는 R2DBC를 더 쉽게 사용할 수 있도록 추상화된 프레임워크를 의미합니다.
- 반응형 애플리케이션 스택에서 관계형 데이터 액세스 기술을 사용하는 Spring 기반 애플리케이션을 더 쉽게 빌드할 수 있게 해 줍니다.
1. Spring Boot Data R2DBC 주요 특징
| 특징 | 세부 내용 |
| Repository 인터페이스 지원 | - ReactiveCrudRepository를 통한 기본 CRUD 메서드 자동 제공 - 메서드 이름 규칙을 통한 쿼리 자동 생성 - @Query 어노테이션을 사용한 리액티브 레포지토리 - Query derivation 지원 |
| 트랜잭션 관리 | - @Transactional 어노테이션을 통한 선언적 트랜잭션 관리 - 리액티브 트랜잭션 매니저를 통한 비동기 트랜잭션 처리 |
| 엔티티 매핑 | - @Table, @Column 등의 어노테이션을 통한 객체-관계 매핑 - 복잡한 도메인 모델의 매핑 단순화 - R2dbcEntityTemplate을 통한 Template API 지원 - DatabaseClient 기반의 Criteria API를 통한 매핑된 엔티티 실행 |
| 자동 구성 | - Spring Boot의 자동 구성을 통한 데이터베이스 연결 설정 간소화 - 별도 설정 없이 R2DBC 즉시 사용 가능 - Functional API 지원 |
| 데이터베이스 지원 | - 다양한 데이터베이스 지원: H2, MariaDB, Microsoft SQL Server, MySQL, jasync-sql MySQL, PostgreSQL, Oracle - 네이티브 문법을 사용한 파라미터 바인딩 - 결과 처리: 업데이트 카운트, 비매핑(Map<String, Object>), 엔티티 매핑, 추출 함수 |
2. Spring Boot Data Interface
2.1. ReactiveCrudRepository
💡 ReactiveCrudRepository Interface
- Spring Data R2DBC에서 제공하는 기본 인터페이스로, 리액티브 프로그래밍 방식의 CRUD(Create, Read, Update, Delete) 작업을 지원합니다.
| 메서드 | 반환 타입 | 설명 |
| count() | Mono<Long> | 전체 엔티티 개수를 반환 |
| delete(T entity) | Mono<Void> | 주어진 엔티티를 삭제 |
| deleteAll() | Mono<Void> | 모든 엔티티를 삭제 |
| deleteAll(Iterable<T>) | Mono<Void> | 주어진 엔티티 목록을 모두 삭제 |
| deleteAll(Publisher<T>) | Mono<Void> | Publisher에서 제공하는 모든 엔티티를 삭제 |
| deleteAllById(Iterable<ID>) | Mono<Void> | 주어진 ID 목록에 해당하는 모든 엔티티를 삭제 |
| deleteById(ID) | Mono<Void> | 주어진 ID에 해당하는 엔티티를 삭제 |
| deleteById(Publisher<ID>) | Mono<Void> | Publisher에서 제공하는 ID에 해당하는 엔티티를 삭제 |
| existsById(ID) | Mono<Boolean> | 주어진 ID에 해당하는 엔티티 존재 여부를 확인 |
| existsById(Publisher<ID>) | Mono<Boolean> | Publisher에서 제공하는 ID에 해당하는 엔티티 존재 여부를 확인 |
| findAll() | Flux<T> | 모든 엔티티를 조회 |
| findAllById(Iterable<ID>) | Flux<T> | 주어진 ID 목록에 해당하는 모든 엔티티를 조회 |
| findAllById(Publisher<ID>) | Flux<T> | Publisher에서 제공하는 ID에 해당하는 모든 엔티티를 조회 |
| findById(ID) | Mono<T> | 주어진 ID에 해당하는 엔티티를 조회 |
| findById(Publisher<ID>) | Mono<T> | Publisher에서 제공하는 ID에 해당하는 엔티티를 조회 |
| save(S entity) | Mono<S> | 주어진 엔티티를 저장하거나 업데이트 |
| saveAll(Iterable<S>) | Flux<S> | 주어진 엔티티 목록을 모두 저장하거나 업데이트 |
| saveAll(Publisher<S>) | Flux<S> | Publisher에서 제공하는 모든 엔티티를 저장하거나 업데이트 |
ReactiveCrudRepository (Spring Data Core 3.4.1 API)
All Superinterfaces: Repository Interface for generic CRUD operations on a repository for a specific type. This repository follows reactive paradigms and uses Project Reactor types which are built on top of Reactive Streams. Save and delete operations with
docs.spring.io
💡 [참고] ReactiveCrudRepository를 이용한 사용예시
package com.blog.springbootwebflux.repository;
import com.blog.springbootwebflux.model.entity.UserEntity;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Repository;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@Repository
public interface UserRepository extends ReactiveCrudRepository<UserEntity, Long> {
Mono<UserEntity> findTbUserByUserId(String userId);
Flux<UserEntity> findTbUserByUserNm(String userName);
}
2.2. R2dbcEntityTemplate
💡 R2dbcEntityTemplate
- SQL 쿼리를 직접 실행하고 결과를 매핑하는 데 사용되는 템플릿 클래스입니다.
- 복잡한 쿼리나 동적 쿼리 실행에 유용합니다.
| 메서드 | 반환 타입 | 설명 |
| count(Query query, Class<?> entityClass) | Mono<Long> | 주어진 쿼리 조건에 맞는 엔티티의 개수를 반환 |
| delete(Class<?> domainType) | ReactiveDeleteOperation.ReactiveDelete | 특정 도메인 타입의 삭제 작업을 위한 빌더를 반환 |
| delete(Query query, Class<?> entityClass) | Mono<Long> | 쿼리 조건에 맞는 엔티티들을 삭제하고 삭제된 개수를 반환 |
| delete(T entity) | Mono<T> | 주어진 엔티티를 삭제하고 삭제된 엔티티를 반환 |
| exists(Query query, Class<?> entityClass) | Mono<Boolean> | 쿼리 조건에 맞는 엔티티의 존재 여부를 확인 |
| getConverter() | R2dbcConverter | R2DBC 변환기를 반환 |
| getDataAccessStrategy() | ReactiveDataAccessStrategy | 데이터 접근 전략을 반환 |
| getDatabaseClient() | DatabaseClient | 데이터베이스 클라이언트를 반환 |
| insert(Class<T> domainType) | ReactiveInsertOperation.ReactiveInsert<T> | 특정 도메인 타입의 삽입 작업을 위한 빌더를 반환 |
| insert(T entity) | Mono<T> | 주어진 엔티티를 삽입하고 삽입된 엔티티를 반환 |
| select(Class<T> domainType) | ReactiveSelectOperation.ReactiveSelect<T> | 특정 도메인 타입의 조회 작업을 위한 빌더를 반환 |
| Flux<T> | select(Query query, Class<T> entityClass) | 쿼리 조건에 맞는 모든 엔티티를 조회 |
| Mono<T> | selectOne(Query query, Class<T> entityClass) | 쿼리 조건에 맞는 단일 엔티티를 조회 |
| void | setApplicationContext(ApplicationContext) | 애플리케이션 컨텍스트를 설정 |
| void | setBeanFactory(BeanFactory) | 빈 팩토리를 설정 |
| void | setEntityCallbacks(ReactiveEntityCallbacks) | 엔티티 콜백을 설정 |
| void | setStatementFilterFunction(Function) | SQL 문 필터 함수를 설정 |
| ReactiveUpdateOperation.ReactiveUpdate | update(Class<?> domainType) | 특정 도메인 타입의 수정 작업을 위한 빌더를 반환 |
| Mono<Long> | update(Query query, Update update, Class<?> entityClass) | 쿼리 조건에 맞는 엔티티들을 수정하고 수정된 개수를 반환 |
| Mono<T> | update(T entity) | 주어진 엔티티를 수정하고 수정된 엔티티를 반환 |
R2dbcEntityTemplate (Spring Data R2DBC 3.4.1 API)
All Implemented Interfaces: Aware, BeanFactoryAware, ApplicationContextAware, FluentR2dbcOperations, R2dbcEntityOperations, ReactiveDeleteOperation, ReactiveInsertOperation, ReactiveSelectOperation, ReactiveUpdateOperation Implementation of R2dbcEntityOper
docs.spring.io
💡 [참고] R2dbcEntityTemplate를 이용한 사용예시
@Service
public class UserService {
private final R2dbcEntityTemplate template;
public UserService(R2dbcEntityTemplate template) {
this.template = template;
}
// SELECT 예시
public Flux<UserEntity> findUsersByName(String name) {
return template.select(UserEntity.class)
.from("tb_user")
.matching(Query.query(where("user_nm").like("%" + name + "%")))
.all();
}
// INSERT 예시
public Mono<UserEntity> saveUser(UserEntity user) {
return template.insert(UserEntity.class)
.into("tb_user")
.using(user);
}
// UPDATE 예시
public Mono<Integer> updateUserName(String userId, String newName) {
return template.update(UserEntity.class)
.inTable("tb_user")
.matching(Query.query(where("user_id").is(userId)))
.apply(Update.update("user_nm", newName));
}
// DELETE 예시
public Mono<Integer> deleteUser(String userId) {
return template.delete(UserEntity.class)
.from("tb_user")
.matching(Query.query(where("user_id").is(userId)))
.all();
}
}
3) Spring Boot Data R2DBC 환경 설정 : PostgreSQL Driver
💡 Spring Boot Data R2DBC 환경 설정 : PostgreSQL Driver
- Spring Boot WebFlux + R2DBC + PostgreSQL 기반의 데이터 처리 과정을 위해서 아래와 같은 처리과정을 구성하였습니다.
- 아래의 과정을 환경설정하고 수행되는 과정에 대해 알아봅니다.
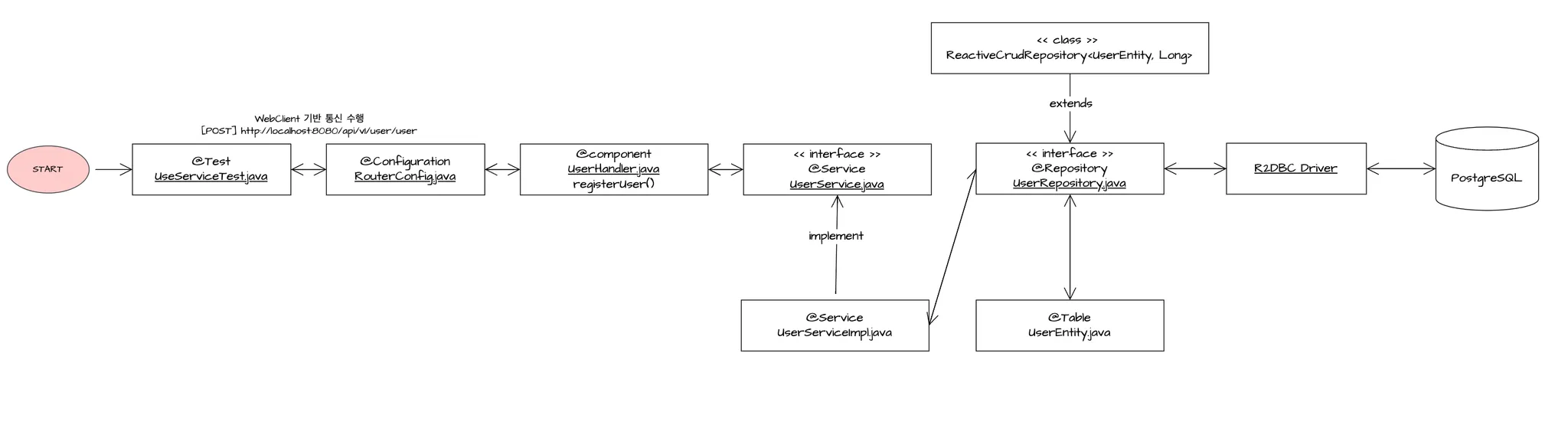
1. 의존성 추가 : build.gradle
💡 의존성 추가: : build.gradle
- spring-boot-starter-webflux: 스프링의 리액티브 웹 프레임워크로, 비동기-논블로킹 웹 애플리케이션을 구축하기 위한 기본 의존성입니다.
- spring-boot-starter-data-r2dbc: Spring Boot에서 R2DBC를 사용하기 위한 기본적인 설정과 인프라를 제공하는 스타터 패키지입니다.
- r2dbc-postgresql: PostgreSQL 데이터베이스와의 실제 연결을 담당하는 구체적인 드라이버입니다. R2DBC는 데이터베이스별로 전용 드라이버가 필요합니다.
dependencies {
implementation "org.springframework.boot:spring-boot-starter-webflux:${bootVer}" // Webflux
implementation "org.springframework.boot:spring-boot-starter-data-r2dbc:${bootVer}" // R2DBC
implementation 'org.postgresql:r2dbc-postgresql:1.0.7.RELEASE' // R2DBC - PostgresSQL
}
[ 더 알아보기 ]
💡 R2DBC SPI는 별도의 설치가 필요 없을까?
- R2DBC PostgreSQL 드라이버(r2dbc-postgresql)는 이미 SPI(Service Provider Interface)를 포함하고 있기에 별도의 설치는 필요 없습니다.
- spring-boot-starter-data-r2dbc와 r2dbc-postgresql 의존성만 추가하면 자동으로 필요한 SPI 구현체가 포함됩니다
2. 설정 파일 추가 : application.yml
💡 설정 파일 추가 : application.yml
- yml 파일 내에 R2DBC 연결 정보를 설정합니다.
- R2DBC r2dbc:url 형식은 'r2dbc:postgresql://{host}:{port}/{database}' 형태를 따릅니다.
- 추가로 R2DBC를 로깅, R2DBC Connection Pool 로깅, R2DBC-PostgreSQL Driver 로깅을 포함하였습니다.
spring:
r2dbc:
url: r2dbc:postgresql://localhost:5432/testdb
username: localmaster
password: qwer1234
logging:
level:
org.springframework.r2dbc: DEBUG # R2DBC 로깅
io.r2dbc.pool: DEBUG # R2DBC Connection Pool 로깅
io.r2dbc.postgresql: DEBUG # R2DBC - PostgreSQL 드라이버 로깅
Getting Started :: Spring Data Relational
Spring Data R2DBC uses a Dialect to encapsulate behavior that is specific to a database or its driver. Spring Data R2DBC reacts to database specifics by inspecting the ConnectionFactory and selects the appropriate database dialect accordingly. If you use a
docs.spring.io
[ 더 알아보기 ]
💡 local postgresql은 jdbc 연결방식과 다르게 설정해야 해?
- 기본적인 데이터베이스 연결과 동일하게 구성합니다. 단, 프로토콜 접두사를 JDBC는 'jdbc:'를 사용하고, R2DBC는 'r2dbc:'를 사용합니다.
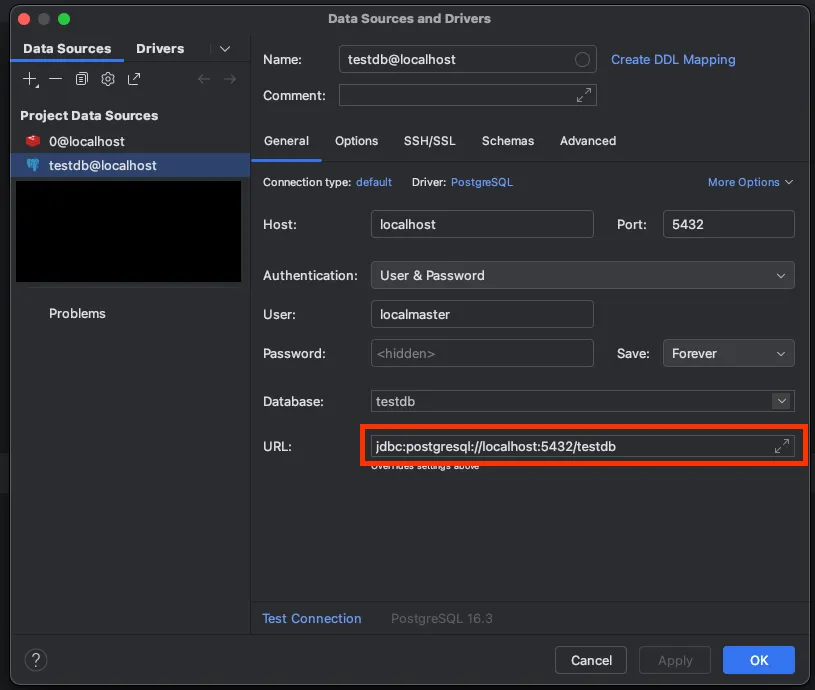
💡 [참고] Local PostgreSQL 데이터베이스 설정방법에 대해 궁금하시면 아래의 글을 참고하시면 도움이 됩니다.
[DB] MacOS에서 PostgreSQL 로컬 데이터베이스 구성 방법
해당 글에서는 PostgreSQL을 로컬 디비로 구성하는 방법에 대해서 공유합니다. 1) PostgreSQL을 설치합니다.💡 PostgreSQL의 버전을 확인하고 설치가 안 되어 있다면 설치를 하고 서비스를 수행합니다.#
adjh54.tistory.com
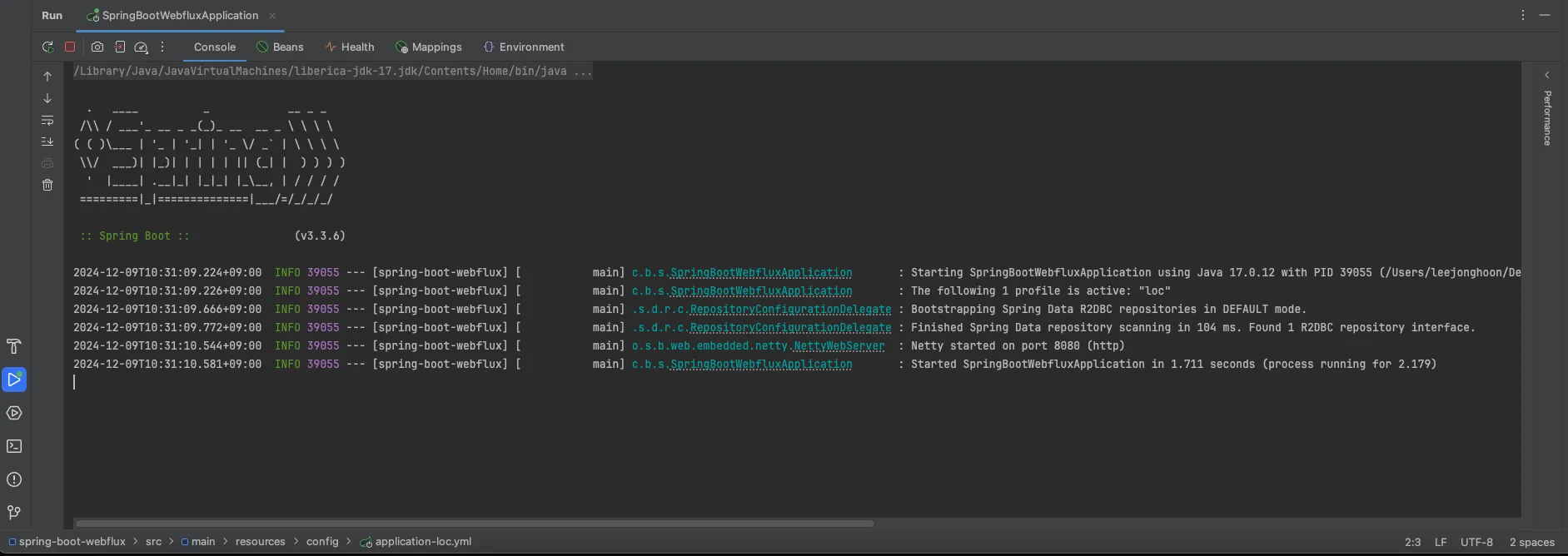
💡 아래와 같이 Spring Boot Webflux에서는 Netty 서버를 통해서 실행이 됨을 확인하였습니다
3. 데이터베이스 쿼리 수행 : Repository
💡 데이터베이스 쿼리 수행 : Repository
- Repository는 ReactiveCrudRepository<T, Long>로부터 상속을 받아서 인터페이스를 구성합니다.
1. findTbUserByUserId
- TB_USER 테이블에 파라미터로 받은 userId를 기반으로 데이터를 Flux 형태(0~N개)로 데이터를 조회하는 인터페이스입니다.
2. findTbUserByUserNm
- TB_USER 테이블에서 파라미터로 받은 userNm을 기반으로 데이터를 Flux 형태(0~N개)로 데이터를 조회하는 인터페이스입니다.
package com.blog.springbootwebflux.repository;
import com.blog.springbootwebflux.model.dto.UserDto;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Repository;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* Please explain the class!!
*
* @author : leejonghoon
* @fileName : UserRepository
* @since : 2024. 12. 5.
*/
@Repository
public interface UserRepository extends ReactiveCrudRepository<UserDto, Long> {
Mono<UserDto> findTbUserByUserId(String userId);
Flux<UserDto> findTbUserByUserNm(String userName);
}
4. 서비스 구성 : Service
💡 서비스 구성 : Service
- 비즈니스 로직을 처리하는 Service를 구성합니다.
4.1. Service Interface
💡 Service Interface
- 간단하게 Repository 내에 사용자 아이디를 기반으로 단건을 조회하거나 사용자 이름을 기반으로 여러 건을 조회하는 간단한 인터페이스 명세서를 구성하였습니다.
package com.blog.springbootwebflux.service;
import com.blog.springbootwebflux.model.entity.UserEntity;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* Please explain the class!!
*
* @author : leejonghoon
* @fileName : UserService
* @since : 2024. 12. 19.
*/
@Service
public interface UserService {
Mono<UserEntity> findUserByUserId(String userId);
Flux<UserEntity> findTbUserByUserNm(String userNm);
}
4.2. Serivce Interface 구현체
💡 Serivce Interface 구현체
- Repository로부터 사용자 아이디 기반으로 사용자 정보를 조회하는 로직과 이름을 기반으로 사용자 정보를 조회하는 비즈니스로직을 구성하였습니다.
package com.blog.springbootwebflux.service.impl;
import com.blog.springbootwebflux.model.dto.MailTxtSendDto;
import com.blog.springbootwebflux.model.entity.UserEntity;
import com.blog.springbootwebflux.repository.UserRepository;
import com.blog.springbootwebflux.service.EmailService;
import com.blog.springbootwebflux.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* Please explain the class!!
*
* @author : leejonghoon
* @fileName : UserServiceImpl
* @since : 2024. 12. 19.
*/
@Slf4j
@Service
public class UserServiceImpl implements UserService {
private final UserRepository userRepository;
private final EmailService emailService;
public UserServiceImpl(UserRepository userRepository, EmailService emailService) {
this.userRepository = userRepository;
this.emailService = emailService;
}
@Override
@Transactional(readOnly = true)
public Mono<UserEntity> findUserByUserId(String userId) {
System.out.println("[+] findUserByUserId 실행 ....");
Mono<UserEntity> userInfo = userRepository.findTbUserByUserId(userId);
userInfo.subscribe(
data -> System.out.println("User data: " + data),
error -> System.err.println("Error: " + error),
() -> System.out.println("Completed")
);
System.out.println("findUserByUserId :: " + userInfo.toString());
return userInfo;
}
@Override
@Transactional(readOnly = true)
public Flux<UserEntity> findTbUserByUserNm(String userNm) {
System.out.println("[+] findTbUserByUserNm 실행 ....");
Flux<UserEntity> userInfo = userRepository.findTbUserByUserNm(userNm);
userInfo.subscribe(
data -> System.out.println("User data: " + data),
error -> System.err.println("Error: " + error),
() -> System.out.println("Completed")
);
System.out.println("findTbUserByUserNm :: " + userInfo.toString());
return userInfo;
}
}
5. 표현 계층 구성 : Router, Handler Function
💡 표현 계층 구성 : Router, Handler Function
- 엔드포인트를 구성하고 표현계층 처리를 수행하는 Router Function과 Handler Function을 구성합니다.
5.1. Router Function
💡 Router Function
- API 엔드포인트를 구성하는 Router Function을 구성하였습니다.
package com.blog.springbootwebflux.config;
import com.blog.springbootwebflux.handler.CodeHandler;
import com.blog.springbootwebflux.handler.UserHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.client.ReactorResourceFactory;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.RouterFunctions;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.netty.resources.LoopResources;
/**
* API Endpoint 관리하는 Router Function입니다.
*
* @author : leejonghoon
* @fileName : RouterConfig
* @since : 2024. 12. 4.
*/
@Configuration
public class RouterConfig {
@Bean
public ReactorResourceFactory reactorResourceFactory() {
ReactorResourceFactory factory = new ReactorResourceFactory();
factory.setUseGlobalResources(false); // 글로벌 리소스 사용 비활성화
factory.setLoopResources(LoopResources.create("event-loop-", 4, true));
return factory;
}
/**
* 사용자 라우터를 구성합니다.
*
* @param userHandler UserHandler
* @param codeHandler CodeHandler
* @return RouterFunction<ServerResponse>
*/
@Bean
public RouterFunction<ServerResponse> userRoutes(UserHandler userHandler, CodeHandler codeHandler) {
return RouterFunctions
.route()
.path("/api/v1", builder -> builder
.path("/user", userBuilder -> userBuilder
.GET("/user/{userId}", userHandler::findTbUserByUserId)
.GET("/users", userHandler::findTbUserByUserNm)
)
)
.build();
}
}
5.2. Handler Function
💡 Handler Function
- Router Function으로부터 전달받은 HTTP 요청을 실제로 처리하는 역할을 담당합니다.
package com.blog.springbootwebflux.handler;
import com.blog.springbootwebflux.model.entity.UserEntity;
import com.blog.springbootwebflux.service.EmailService;
import com.blog.springbootwebflux.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.server.ServerRequest;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.util.List;
/**
* 사용자 Handler Function
*
* @author : leejonghoon
* @fileName : UserHandler
* @since : 2024. 12. 4.
*/
@Slf4j
@Component
public class UserHandler {
private final UserService userService;
public UserHandler(UserService userService) {
this.userService = userService;
}
/**
* 사용자 아이디를 기반으로 단건 사용자를 조회합니다.
*
* @param request
* @return
*/
public Mono<ServerResponse> findTbUserByUserId(ServerRequest request) {
String userId = request.pathVariable("userId");
return userService.findUserByUserId(userId)
.flatMap(user -> ServerResponse.ok()
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(user))
.doOnNext(response -> log.info("Found user for userId: {}", userId))
.doOnError(error -> log.error("Error finding user: {}", error.getMessage()))
.switchIfEmpty(Mono.defer(() -> {
log.info("No user found with ID: {}", userId);
return ServerResponse.notFound().build();
}));
}
/**
* 사용자 이름을 기반으로 단건 사용자를 조회합니다.
*
* @param request
* @return
*/
public Mono<ServerResponse> findTbUserByUserNm(ServerRequest request) {
return request.queryParam("userNm")
.map(userNm -> userService.findTbUserByUserNm(userNm)
.collectList()
.flatMap(users -> {
if (users.isEmpty()) {
return ServerResponse.notFound().build();
}
return ServerResponse.ok()
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(users);
})
.doOnNext(response -> log.info("Found users for userNm: {}", userNm))
.doOnError(error -> log.error("Error finding users: {}", error.getMessage())))
.orElse(ServerResponse.badRequest()
.bodyValue("userNm parameter is required"));
}
}
4) Spring Boot Data R2DBC 결과화면
1. Endpoint 확인
| Endpoint | HTTP Method | 설명 |
| http://localhost:8080/api/v1/user/user/{userId} | GET | 사용자 아이디를 기반으로 사용자 정보를 조회합니다.(단건) |
| http://localhost:8080/api/v1/user/users | GET | 사용자 이름을 기반으로 사용자 정보들을 조회합니다.(다건) |
2. API 호출
💡 API 호출
- 구성한 R2DBC Driver를 기반으로 PostgreSQL 데이터베이스를 통해서 데이터가 조회됨을 확인하였습니다.
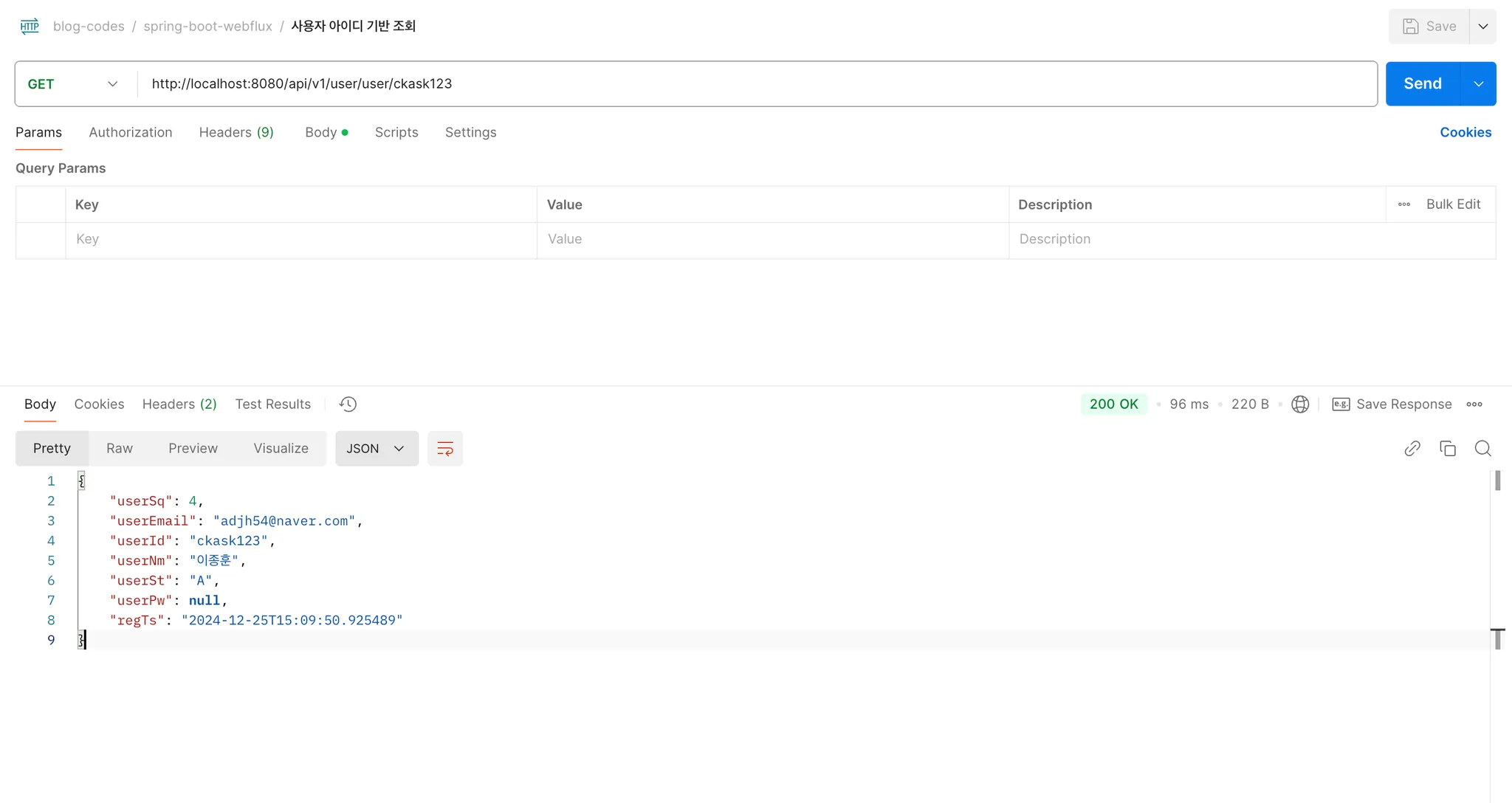
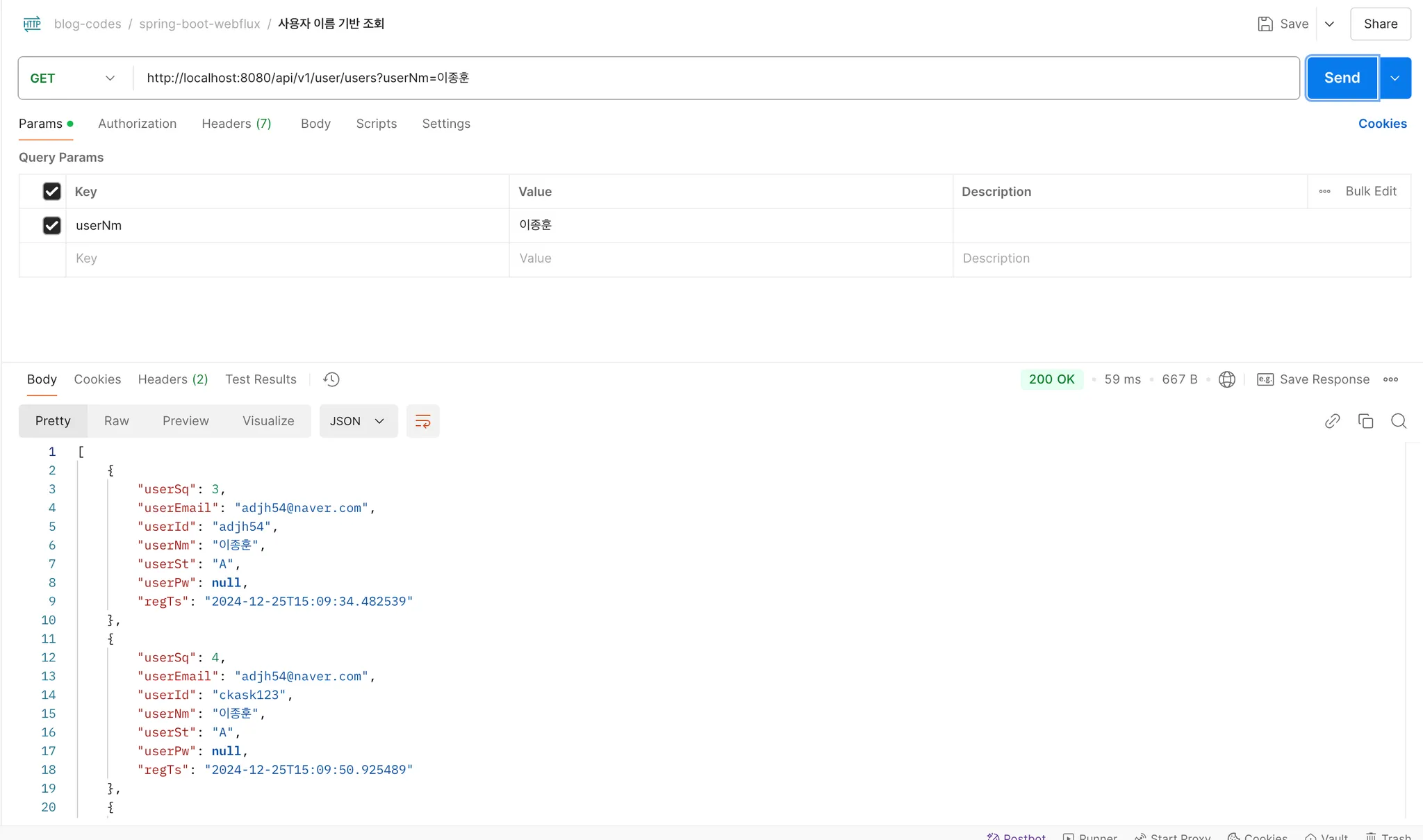
5) Spring Boot Data R2DBC 결과화면 -2 : 비동기 병렬처리
💡 Spring Boot Data R2DBC 결과화면 -2 : 비동기 병렬처리
- R2DBC를 이용하여 비동기 병렬처리되는 과정에 대해서 알아봅니다.
1. 비동기 병렬 처리 테스트 코드
💡 비동기 병렬 처리 테스트 코드
- 이전에 구성한 서비스 로직을 호출하여 아래와 같이 총 0번에서 10번까지 수행하면서 10명의 사용자를 List 객체 내에 구성하였습니다.
- 이를 순회하면서 호출하여서 비동기 병렬로 처리가 되는지 확인해 봅니다.
@Test
public void testParallelProcessing() {
WebClient client = WebClient.create("http://localhost:8080");
// 10명의 서로 다른 사용자 데이터 생성
List<UserEntity> users = IntStream.range(0, 10)
.mapToObj(i -> UserEntity.builder()
.userId("testIdd" + i)
.userEmail("adjh54@naver.com")
.build())
.collect(Collectors.toList());
// 각 사용자에 대해 테스트 실행
StepVerifier.create(
Flux.fromIterable(users)
.flatMap(user ->
client.get()
.uri("/api/v1/user/user/{userId}", user.getUserId())
.accept(MediaType.APPLICATION_JSON)
.exchange()
.thenReturn(Integer.class)
.elapsed()
)
)
.expectNextCount(10)
.verifyComplete();
}
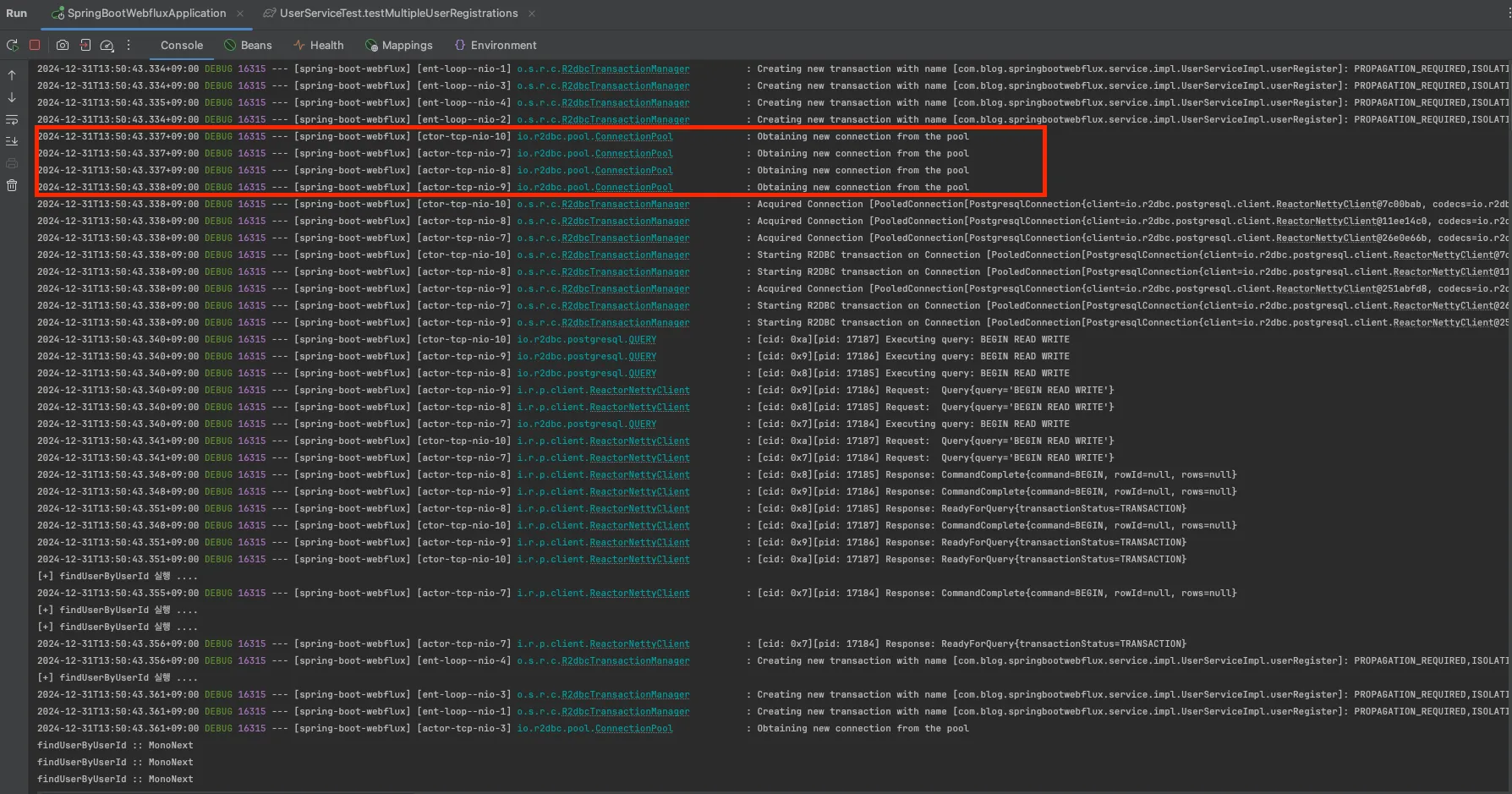
2. 처리결과 화면
💡 처리결과 화면
- 아래의 결과를 확인하면 여러 개의 nio 스레드가 동시에 실행됨을 확인할 수 있습니다 (event-loop--nio-10,7,8,9)
- 각각의 트랜잭션이 독립적으로 생성되고 실행됨을 볼 수 있습니다
- SQL 실행이 여러 actor-tcp-nio 스레드에서 병렬로 이루어지고 있음을 확인할 수 있습니다
- 트랜잭션의 커밋도 여러 스레드에서 동시에 진행되는 것을 볼 수 있습니다
오늘도 감사합니다😀

'Java > WebFlux' 카테고리의 다른 글
| [Java] Spring Boot WebFlux 활용하여 구현하기 -3: Publisher/Subscriber 데이터 처리 타입, 에러 핸들러, 백프레셔 (0) | 2024.12.29 |
|---|---|
| [Java] Spring Boot WebFlux 활용하여 구현하기 -2: 계층구조 및 활용예시 (1) | 2024.12.28 |
| [Java] Spring Boot WebFlux 이해하고 구현하기 -1 : 반응형 프로그래밍에서 WebFlux까지 흐름 (2) | 2024.12.22 |
| [Java] Spring Boot Webflux 이해하기 -2 : 활용하기 (2) | 2023.08.13 |
| [Java] Spring Boot Webflux 이해하기 -1 : 흐름 및 주요 특징 이해 (5) | 2023.08.09 |